
When enterprises commission datasets for AI training, they consistently ask for the same four things:
high quality, large volume, fast delivery, and cost efficiency.
At first glance, quality and speed appear to be in tension. Achieving high-quality datasets requires time, expertise, and careful validation, while rapid delivery often risks compromising precision. Much like a craftsman refining a tool to perfectly fit the hand, dataset quality is determined by countless small refinements accumulated over time.
Since the emergence of ChatGPT in late 2022, the pace of AI development has accelerated dramatically. Model update cycles have shortened, while model sizes and complexity continue to grow. In this environment, the ability to deliver high-quality datasets at scale and speed has become a critical requirement for AI advancement.
Datasets Are the Textbooks of AI Models
Datasets function much like textbooks for students. If a textbook contains incorrect information, the student will learn those inaccuracies, and reproduce them in exams.

The same principle applies to large language models. If an LLM is trained on flawed or inaccurate data, it will confidently generate responses that appear plausible but are ultimately incorrect.
For this reason, data validation is fundamental.
What Should Be Validated in a Dataset?
Flitto collects text, image, and voice data through Arcade, its global crowdsourcing platform.
Participation requirements vary depending on the dataset type. For example:
- Parallel corpus tasks require multilingual proficiency and are accessible only after internal qualification tests.
- Chatting or speaking tasks are open to native speakers, enabling rapid data collection at scale.
Regardless of data type, every dataset must undergo structured validation before it is approved for AI training.
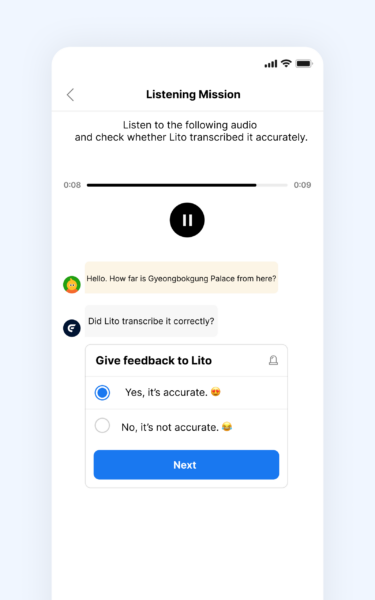
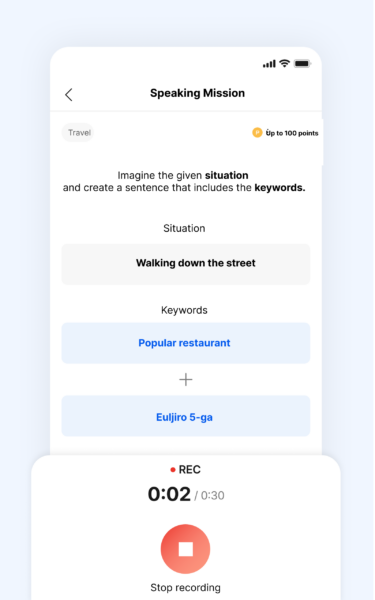
1. Personal Data Screening
The first validation step is ensuring that no personal data is included.
There have been real-world cases where AI services were suspended after models unintentionally generated responses containing names, phone numbers, or other sensitive information. As awareness of data privacy increases globally, preventing such risks has become essential.
Potential personal data includes:
- Names, phone numbers, email addresses, physical addresses
- Bank account or credit card numbers
- Sensitive information embedded unintentionally in images or voice recordings
Because personal data can appear in unexpected forms—such as typos in spoken language or background details in images—systematic screening is critical.
2. Quality Validation
Once personal data risks are addressed, datasets undergo quality validation tailored to each data type.
- Parallel corpus data is reviewed to ensure that translations preserve the original meaning, context, and nuance without omissions.
- OCR and image datasets must ensure that images and textual descriptions accurately correspond. Poor readability or mismatched labels reduce training effectiveness.
- Speech datasets require clear pronunciation and minimal noise to ensure reliable speech recognition.
- STEM and reasoning datasets must include logically sound intermediate steps, not just final answers. Errors or logical gaps directly degrade model performance.
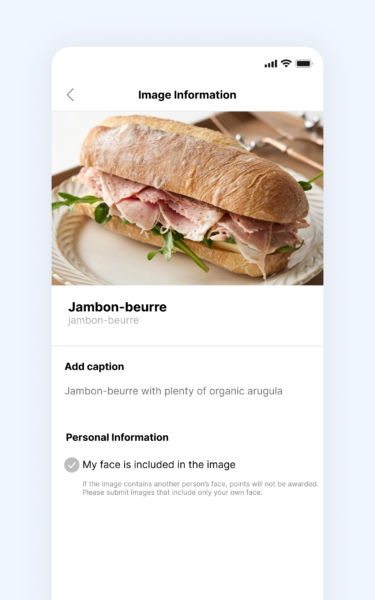
As AI training data has evolved from simple labeling tasks to complex reasoning and domain-specific knowledge, validation now requires professional expertise rather than mechanical review.
How Does Flitto Validate Data at Scale?
Arcade operates on a human-in-the-loop validation structure.
- Users not only create data but also review and evaluate datasets generated by other participants.
- Data that passes peer review is then subjected to final validation by Flitto’s internal project managers and domain specialists.
As project volume and dataset diversity increased, Flitto introduced AI-assisted pre-filtering models trained on over a decade of data construction experience. These models automatically screen out data that fails to meet minimum quality thresholds before human review.
While AI models are not perfect, their accuracy improves continuously as more validated data is accumulated—significantly reducing bottlenecks and accelerating delivery without compromising quality.
Summary
High-quality datasets are the foundation of reliable AI systems.
Flitto Arcade enables scalable data construction by combining global user participation, AI-assisted validation, and expert human review.
This platform-driven approach has supported Flitto’s expansion into global AI data markets, contributing to milestones such as the USD 7 million Export Tower Award in 2025 and Korea’s first TTA certification for Chain-of-Thought datasets.
In the next chapter, we will explore how these validated datasets are systematically managed and maintained for long-term AI deployment.