
Artificial intelligence was once something we could only encounter in science fiction movies or novels. Today, however, AI technologies have become deeply embedded in our daily lives, rapidly transforming the way we live and work. Instead of searching for information, people now open generative AI applications and ask questions directly. Images and videos that previously had to be created manually can now be generated simply by describing what is needed. In the early stages, AI-generated outputs often contained awkward or unnatural elements, making it easy to tell that they were machine-created. Today, however, the technology has become so sophisticated that the difference is often indistinguishable.
Artificial intelligence did not gain these capabilities from the beginning. AI models were trained using datasets such as text, images, and speech, and humans directly evaluated whether the outputs were appropriate or not. By incorporating this feedback, AI learned how to respond more accurately. Through repeated iterations, the accuracy of AI steadily improved, and it is now expected that Artificial General Intelligence (AGI) may emerge in the not-too-distant future.
Datasets Required for AI Training
The term “artificial intelligence” may seem relatively recent, but it was first coined in 1956 when researchers gathered at Dartmouth College to hold a workshop and formally define the concept of AI. Considering that this discussion took place at a time when even basic computers were scarce, the establishment of AI as a concept was a remarkable achievement.

Early AI systems were capable of performing only specific tasks. A representative example is spam filtering, which determines whether incoming emails should be classified as spam and moved out of the inbox. Other examples include AI models that classify handwritten digits from 0 to 9, identify animals in images, or convert spoken language into text. Each of these models was designed to perform a single function, and training datasets were constructed accordingly.
The more data available for training, the better the resulting model performance. However, building such datasets requires substantial human effort. To create a model that automatically classifies spam, each collected email must be manually labeled as spam or non-spam. Similarly, to train a model that identifies animals in images, humans must review each image and annotate the corresponding animal names. Constructing these datasets requires significant time, cost, and manpower, yet AI companies demand datasets that can be built quickly, cost-effectively, and at high quality.
Methods for Building AI Training Datasets
Flitto began as a service that translated tweets posted by celebrities on Twitter (now X) into multiple languages. At the time, K-pop artists such as Super Junior and Psy were gaining global popularity. While international fans followed these artists on social media, they often could not understand the content of their posts and relied instead on translations shared within local fan communities.
One might wonder why machine translation was not used, but in 2010, translation quality was far from reliable. It was not until the emergence of neural machine translation that services such as Google Translate experienced a dramatic improvement in quality, beginning around 2016.
Recognizing this gap, Flitto brought social media content onto its platform and initially relied on internal staff to translate Korean posts into English. As English translations became available, more users joined the platform, and many began translating the English content into their own native languages, such as Vietnamese, Thai, and Indonesian. Because translation does not have a single definitive answer, translations could be collaboratively refined. If one user’s translation was inaccurate or awkward, another user could revise it, resulting in highly accurate multilingual translations of K-pop content.
As Flitto observed that translation data could be organically generated through crowdsourcing, the company expanded beyond celebrity tweet translation and developed a platform called Arcade, which enables data collection through a wide variety of tasks. Users who initially joined Flitto to view translated K-pop content naturally flowed into Arcade, where they were rewarded with points based on their activities. This incentive structure encouraged continuous participation rather than one-time contributions.
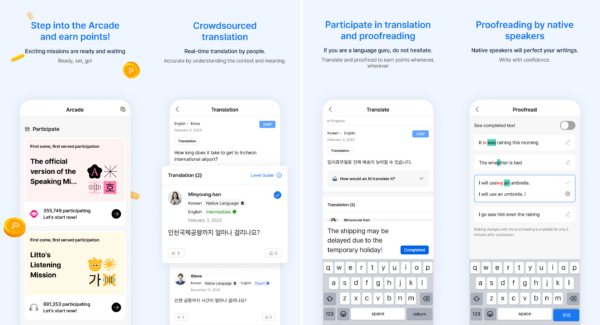
In its early stages, Arcade focused on collecting multilingual parallel corpora. Parallel corpora are essential for building machine translation models. While European languages such as English, French, and Spanish benefit from abundant official documents and meeting records, parallel data for low-resource languages or colloquial expressions is extremely limited. Due to the characteristics of Arcade’s user base, Flitto was able to efficiently collect such data. What is often a weakness for other data providers became a competitive advantage for Flitto, enabling the rapid construction of parallel corpora and leading to the acquisition of both domestic and international enterprise clients.
After developing Arcade to support the construction of parallel corpora, Flitto gradually expanded the platform to accommodate new data types. These included speech tasks, such as reading provided sentences aloud, as well as image tasks that involve collecting images containing text. While translation tasks require proficiency in at least two languages, speech recording and image collection tasks can be performed by virtually anyone, making them particularly suitable for building large-scale datasets.
Expansion into LLM Training Datasets
With the emergence of Large Language Models (LLMs), the types of datasets required for training have also evolved. Previously, translation datasets consisted of source texts and their corresponding translations, while OCR datasets required highly structured formats, including images, character coordinates, and labels. LLMs, however, learn language in a way that more closely resembles human learning. By processing books, news articles, and other long-form content, they capture relationships between words and understand how sentences connect to form broader context. Because LLMs already possess foundational linguistic knowledge, their training datasets are increasingly structured in the form of questions and answers, similar to how humans study.

Following the release of ChatGPT in late 2022, public interest in generative AI surged. At the time, people were amazed by ChatGPT’s ability to respond confidently to virtually any question. However, many of these responses were not always accurate. This raised a critical challenge regarding how to improve model reliability. AI companies have pursued multiple approaches, including increasing the number of parameters, training on larger datasets, and adopting techniques such as Chain-of-Thought (CoT) datasets.
Compared to earlier task-specific AI models, LLMs contain an unprecedented number of parameters, requiring training datasets at an entirely different scale. To address this demand, Flitto enhanced Arcade with features tailored to different dataset types. In addition to its existing user base, Flitto recruited participants with STEM (Science, Technology, Engineering, and Mathematics) backgrounds, as well as users capable of evaluating complex questions and identifying errors or improvements in model responses. This effort expanded the qualified contributor pool and enabled the construction of more advanced datasets.
Building on its extensive experience in dataset construction through Arcade, Flitto participated in a consortium with Upstage in the second half of 2025 as part of the K-AI sovereign foundation model development project. In this initiative, Upstage developed a 100B-parameter model from scratch, and Flitto contributed to achieving performance levels sufficient to pass the project’s first evaluation stage.
Summary
So far, we have examined how Flitto has been able to collect large volumes of data within a relatively short period of time. While data quantity is important, data quality is equally critical. High-quality datasets lead to improved model performance, whereas poor-quality data can significantly degrade results. In the next installment, we will explore how Flitto manages and ensures the quality of its datasets.