
Large Language Models have significantly advanced machine translation performance.
As model sizes scale from billions to trillions of parameters, benchmark scores continue to rise—but so do computational costs and deployment complexity.
Is bigger always better?
In mobile, on-device, and cost-sensitive enterprise environments, efficiency becomes as critical as accuracy. When supported by high-quality parallel corpora and domain-aware data design, small language models can deliver competitive translation performance while remaining practical to deploy.
In this fourth installment of Data Deep Dive, we explore how small language models are reshaping machine translation strategy, and why data remains the decisive factor behind model performance..
As technology advances, machine translation has undergone significant changes. From RBMT (Rule-Based Machine Translation), which translated based on linguistic rules systematized by linguists, to SMT (Statistical Machine Translation), which generated translation rules through statistical analysis of large-scale language data, the field has evolved to NMT (Neural Machine Translation), which utilizes artificial neural networks.
Recently, machine translation using Large Language Models (LLMs) has also been actively researched. Many large language models are being developed for research and commercial use. As competition over the number of parameters intensifies, models have progressed from tens of billions to hundreds of billions, and now even to trillions of parameters.
While large language models with a vast number of parameters can achieve strong performance, they require significant GPU resources to operate and demand substantial time and cost for training. In particular, such models are difficult to deploy on personal mobile devices, making them unsuitable for mobile environments.
Recently, there have been increasing attempts to optimize smaller language models for specific purposes. The “Arabic–English translation model” introduced below follows this approach. As Flitto also provides its own English–Arabic translation model, we will examine its characteristics in detail.
Arabic ↔ English Translation Model ‘Mutarjim’
- Mutarjim: A bidirectional Arabic–English translation model based on Kuwain-1.5B
LLMs can understand multiple languages by being trained on various languages such as English, Spanish, French, German, Chinese, Japanese, and Korean. However, since the amount of training data varies by language, performance may be strong in certain languages—such as English—but relatively lower in others. In some cases, LLMs may barely understand certain languages.
Traditionally, machine translation models have used an “Encoder–Decoder Model.” To build a model that translates from Korean to English, for example, a large-scale parallel corpus is required. Such a corpus consists of Korean sentences and their corresponding English translations.
Korean: 나는 학교에 갑니다.
Korean: 오늘 날씨는 매우 좋습니다.
English: I go to school.
English: The weather is very nice today.
Using a parallel corpus, the model can be trained in a Sequence-to-Sequence (Seq2Seq) manner to learn how a sentence in one language should be generated in another language.
With the emergence of LLMs, decoder-only models have also become widely used. In a decoder-only model, given a sentence, the model generates text by predicting the next most probable token. While decoder-only models are particularly suited for generating narratives, they are also used to build translation models through fine-tuning so that they generate corresponding translated sentences when given an input sentence.
A comparison between encoder–decoder models and decoder-only models used in machine translation is shown below.
| Category | Encoder–Decoder Model | Decoder-Only Model |
| Architecture | Encoder + Decoder | Decoder |
| Objective | Transform an input sequence into an output sequence | Generate natural language text based on given text |
| Training Method | Learn the relationship between input and output using large-scale parallel corpora | Pre-trained on large-scale monolingual data, then fine-tuned using parallel corpora |
| Characteristics | Accurate and consistent sentence-level translation | Able to respond to diverse translation requirements through prompts |
<Table 1. Comparison between Encoder–Decoder Model and Decoder-Only Model>
Mutarjim is a bidirectional Arabic–English translation model trained on Arabic–English parallel corpora, using the decoder-only model Kuwain-1.5B as its base model.
- Kuwain-1.5B: A 1.5B-parameter small English language model trained through language injection by incorporating Arabic data.
Training Method of Mutarjim
The base model Kuwain-1.5B was originally trained in English and later injected with Arabic text to enable it to understand Arabic. However, knowing English and Arabic does not automatically mean knowing how English translates into Arabic, or vice versa.
Mutarjim was trained in two stages. First, it was trained on 10 billion Arabic–English tokens. Subsequently, it was fine-tuned using 6 million refined Arabic–English parallel data samples.
Since Kuwain-1.5B is a decoder-only model, training is conducted by predicting the next token in a given sequence. To distinguish languages, special tokens such as <Arabic> and <English> were introduced and inserted into the parallel corpus to construct the training dataset.

As shown in the figure above, in the initial training phase, <Arabic> and <English> tokens were placed before Arabic and English sentences, respectively. To support both Arabic-to-English and English-to-Arabic translation, the order of sentences was mixed appropriately so that either language could appear first.
After the initial training phase, the dataset format was modified to resemble that of encoder–decoder models for fine-tuning, enabling the LLM to more clearly understand translation tasks.
Arabic–English Benchmark Dataset Tarjama-25
- Tarjama-25: An Arabic–English dataset composed of approximately 5,000 parallel sentences, including sentences related to Islamic contexts.
Existing Arabic–English benchmark datasets have often been constructed by translating English sentences into Arabic. As a result, these datasets did not sufficiently reflect the cultural characteristics of Islamic contexts where Arabic is widely used. Along with the release of Mutarjim, the Tarjama-25 Arabic–English benchmark dataset was also introduced.
Tarjama-25 consists of approximately 5,000 parallel sentences, with part of the dataset originally constructed in Arabic. Additionally, 5.9% of the corpus includes sentences related to Islamic contexts, allowing for more accurate evaluation of Arabic machine translation performance.
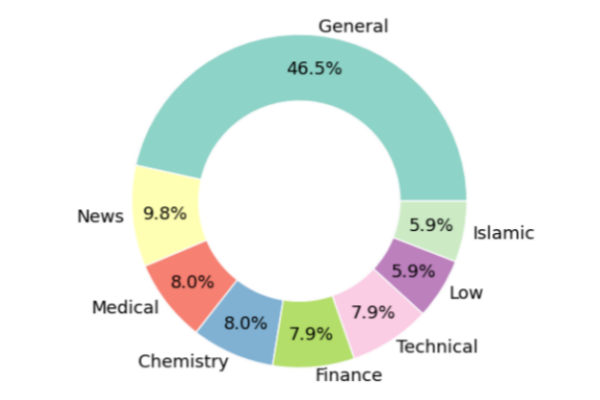
<Figure 2. Domain Distribution of Tarjama-25>
Since Flitto also provides bidirectional Arabic ↔ English machine translation, we compared the COMET scores of Mutarjim and Flitto using the Tarjama-25 dataset.
- COMET: A translation quality evaluation metric developed by Unbabel. Unlike BLEU, which measures word overlap, COMET converts text into vector representations using neural networks and evaluates semantic similarity.
| Model | Method | Number of Parameters | Arabic → English Translation (COMET Score) | English → Arabic Translation (COMET Score) |
| Mutarjim | LLM | 1.5B | 82.63 | 83.41 |
| Flitto | NMT | 0.2B | 73.18 | 78.77 |
<Table 2. Comparison of Translation Scores between Mutarjim and Flitto Machine Translation Models>
Although direct comparison is challenging because Mutarjim is based on an LLM architecture while Flitto’s translation model is based on NMT, Mutarjim was trained to achieve high performance as a small language model, whereas Flitto’s translation model uses a smaller number of parameters.
Mutarjim achieved higher scores in both Arabic-to-English and English-to-Arabic translation. Since the Tarjama-25 benchmark includes Islamic-related sentences, and Flitto’s training dataset contains relatively fewer parallel corpora in that domain, this may have contributed to the observed results.
Flitto is currently developing an Arabic ↔ English translation model based not only on NMT but also on LLM architecture. By referencing the training methodology of Mutarjim, Flitto aims to provide even more advanced machine translation models.