
On August 8, just days after OpenAI released GPT-5, Elon Musk posted on X:
“Grok 4 Heavy was smarter two weeks ago than GPT-5 is now and G4H is already a lot better.”
Why Did Grok Perform So Well?

In the highly competitive landscape of generative AI models, how was Grok able to earn recognition for its performance? The answer, in one word, is data.
Grok specifically benefits from real-time access to X’s data streams. As confirmed on X’s official site, Grok was pre-trained by xAI on a variety of publicly available sources and curated datasets, but it continues to adapt through live social content, capturing trending terms, emerging entities, and evolving discourse.
This real-time data stream is often cited as a key factor behind Grok’s performance.
The Truth in AI: Data Defines Performance
As generative AI spreads, people often compare model performance, debating Gemini, GPT, or Grok. Yet the real key to performance is not the model itself. It is the data.
Research consistently highlights three critical dimensions of training data that directly impact AI performance:
- Quality: High-quality data improves accuracy, robustness, and generalizability (Evaluating the Impact of Data Quality on Machine Learning Model Performance).
- Scale: Scaling laws show that more data leads to better model performance—if curated effectively (Beyond Bigger Models: The Evolution of Language Model Scaling Laws).
- Timeliness: Data must be continuously refreshed to capture new vocabulary, entities, and context, ensuring relevance in real-world deployment (Overview of Data Quality: Examining the Dimensions, Antecedents, and Impacts of Data Quality).
Together, these three elements define the competitive edge of any LLM ecosystem.
📣Among these, quality is often the most decisive factor. A 2024 Nature study found that improving dataset quality yielded more consistent gains than changes in model architecture (Nature, 2024).
As Flitto CEO Simon Lee has emphasized, even the most brilliant brain cannot excel without the right textbook. In AI, that textbook is data, and the quality of that data ultimately determines how well the model performs.
A decade ago, the idea of buying and selling datasets was uncommon. But landmark moments like AlphaGo (2016) and ChatGPT (2022) reshaped perceptions worldwide, making it clear that AI breakthroughs are grounded in high-quality data.
Flitto, founded in 2012, was ahead of this curve. As The Korea Times reported in 2018, the company rapidly grew by selling high-quality language data collected through human translations, serving clients like NTT DoCoMo, Baidu, Tencent, Microsoft, and Expedia
And today, quality means far more than accuracy. Enterprises are demanding hyper-personalized, domain-specific, and contextually rich datasets:
- low-resource languages such as Tagalog or Khmer,
- specialized domain text with complex structures,
- speech data segmented by noise level, decibel, gender, and region.
In short, modern AI performance depends not on volume alone, but on specialized, high-fidelity datasets tailored to real-world scenarios.
Flitto’s Competitive Edge in Data
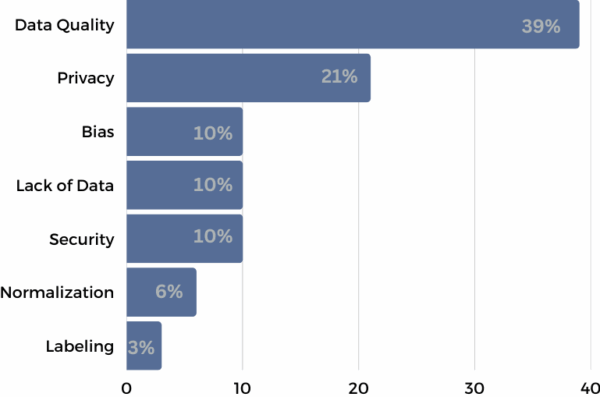
At Flitto, we have spent more than a decade building data infrastructure designed around the three critical dimensions of quality, scale, and timeliness.
Data Quality
- Human-in-the-loop validation: Every dataset passes through a five-stage QA process with project managers, domain experts, and peer reviewers.
- Proven accuracy: Our multilingual datasets achieve 99.8% accuracy, validated by expert review and customer adoption.
- Trusted globally: Selected by global big techs and public institutions.
👉 High-fidelity datasets, trusted by the industry.
📣 Most recently, this commitment was validated when the Telecommunications Technology Association (TTA) awarded Flitto’s Chain-of-Thought dataset Korea’s first official data quality certification.
Data Scale
- Coverage across 173 countries and 42 languages, powered by a community of 14 million+ contributors.
- Processing 1.2 billion+ tokens annually, delivering large-scale corpora for LLM training.
- 2,900+ enterprise projects completed, covering rare languages and domain-specific data.
- Multi-format capabilities: parallel corpora, speech, OCR, coding, RLHF, and multimodal datasets.
👉 Comprehensive data coverage at global scale.
Data Timeliness
- Continuous data flow from live services, Live Translation and Chat Translation.
- Real-time user interactions captured, refined, and fed back into the data pipeline.
- A sustainable feedback loop ensures Flitto’s datasets always reflect the latest language trends, terminology, and entities.
👉 A living data ecosystem.
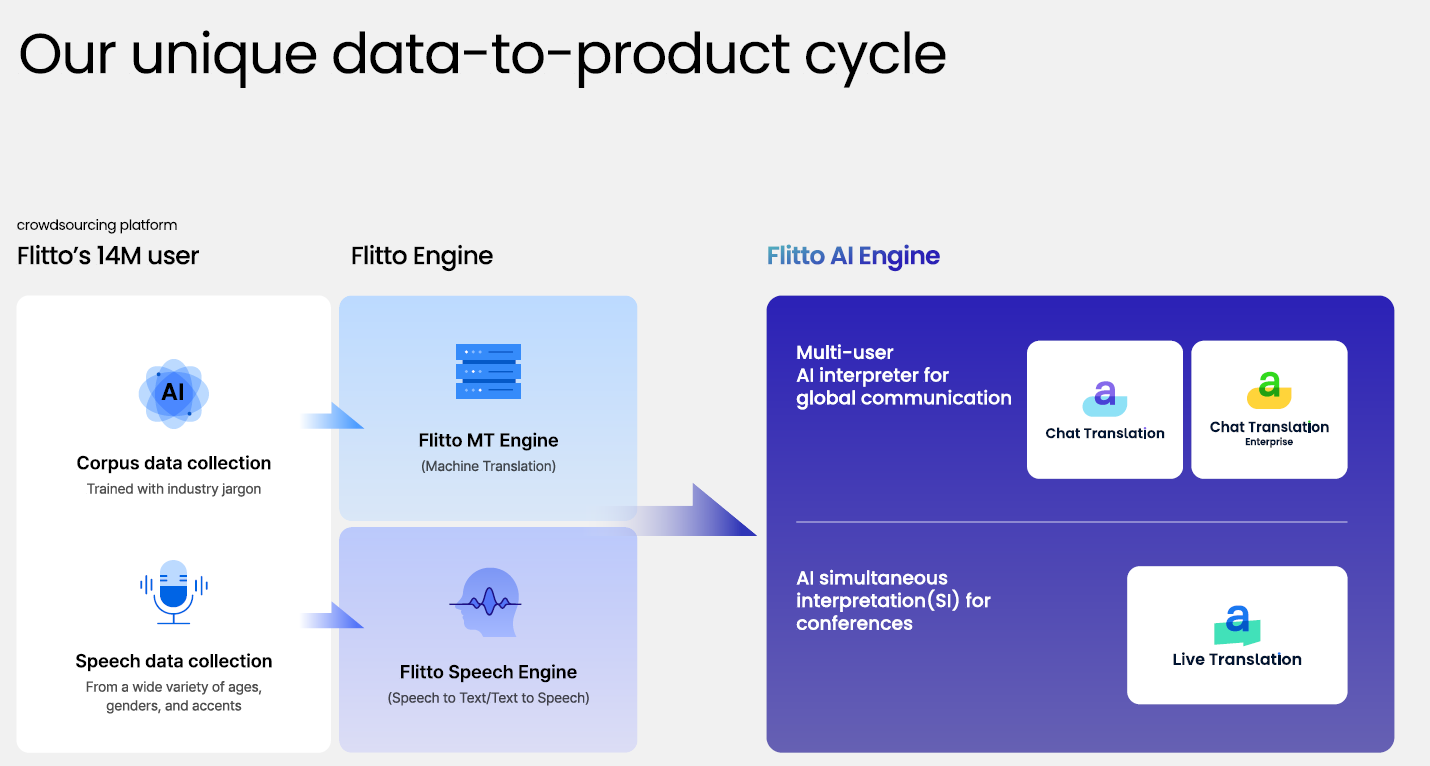
Together, these three dimensions come to life in Flitto’s data flywheel.
The flywheel connects every stage of AI development, collection, refinement, training, and service. Data captured from real-world services like Chat Translation and Live Translation is continuously fed back into the pipeline, ensuring that our models stay aligned with evolving language and usage.
The market is already validating Flitto’s data competitiveness. According to industry reports, Flitto’s data revenue and per-unit pricing have steadily increased year over year.
Growth in both topline and pricing reflects one truth: the market values quality, scale, and timeliness, and Flitto delivers on all three.
Flitto as a Data Infrastructure Partner
As Grok’s case illustrates, access to high-quality, timely data is the decisive factor in LLM performance. Among the three dimensions, quality matters most, and this is where Flitto’s strength is proven.
In today’s increasingly competitive generative AI race, true advantage comes from the data that fuels the model. And this is where Flitto stands out. As a global data infrastructure company, Flitto powers the next generation of AI.