
Over the past four weeks, we have published a Deep Dive series designed to provide a comprehensive understanding of Flitto. Through this series, we aimed to clearly articulate the foundation of Flitto’s identity as a data company, the strength of our data assets, our data-driven solutions, and our long-term vision toward hyper-personalized AI communication.

Here is the full story of the Flitto Deep Dive series.
[Flitto Deep Dive 1] Why Flitto’s Founder Became Deeply Committed to “Beyond Language Barriers”
Steve Jobs’s philosophy of human-centered design materialized in Apple’s intuitive UI/UX and its end-to-end experience architecture.
Jeff Bezos’s customer obsession became the foundation of Amazon’s review-driven, trust-based purchasing experience.
Similarly, a founder’s worldview offers one of the most powerful lenses for understanding a company’s identity. Management research consistently notes that a founder’s philosophy becomes embedded in the organization’s operating DNA, shaping its long-term direction and identity (Stinchcombe, 1965; Baron et al., 1999).
From this perspective, exploring the formative experiences that led CEO Simon Lee to envision a “world beyond language barriers” provides valuable context for understanding Flitto’s mission, business architecture, and long-term vision.
Simon Lee’s story begins in his childhood. Born in Kuwait in 1982, he grew up across Saudi Arabia, the United States, and the United Kingdom, following his father’s overseas assignments. Being immersed in multilingual environments from an early age made him realize that language is more than a tool for communication, it is a resource fundamentally tied to culture, education, and opportunity.

This awareness later crystallized into Flitto’s long-standing slogan, “Beyond Language Barrier,” used consistently since the company’s founding in 2012. It would eventually become the cornerstone of Lee’s leadership philosophy and the company’s vision.
Early Experiments Connecting People Who Needed and Could Provide Language Help
After returning to Korea at age seventeen and attending Daewon Foreign Language High School, Lee entered Korea University as a business major. His relationship with languages continued: fluent in English, French, and other foreign languages, he often helped classmates with translation-related assignments, sometimes in exchange for meals.
This experience sparked a question:
“There are many people who are good at languages, and many who need translation help. What if we simply connected the two?”
During a period when web services and online platforms were rapidly emerging, Lee built his own server and began operating an early version of such a matching system.
As student council president, he organized a pool of multilingual peers, collected translation requests submitted by students, and allowed capable peers to answer them in exchange for small rewards.
This peer-to-peer structure became the conceptual foundation for what would later evolve into the Flitto service.
Flying Cane: The First Step Toward a Scalable Translation Platform
Based on these early experiences, Lee launched Flying Cane after graduating from university, a platform that combined “travel” and “translation.” Users uploaded travel-related translation requests, and participants provided the translations. It was, in essence, a continuation of the student-run system he had operated earlier.
The choice of travel as the core theme was deliberate. Travel situations expose the essence of language barriers most intuitively, and the translation needs, directions, food orders, transport, reservations, tend to be simple and universal, encouraging broad user participation.
As expected, participation grew rapidly, enabling the collection of substantial translation data in a short period.
Seeing the community expand reinforced Lee’s belief that:
“This idea must eventually become a real business.”
In 2009, he even published his translation-platform concept online, stating that anyone could freely use it, yet no one executed it.
That silence strengthened his resolve:
“Then I will build it myself.”
From Internal Venture to Independent Startup
At that time, an SK Telecom representative who had been following his idea introduced him to the company’s internal venture program. Lee joined SK Telecom under the condition that his translation platform could be proposed through the initiative.
His main responsibilities involved discovering and evaluating global startups for potential investment, but through the internal venture program DoDream, he formally presented the translation-platform concept, laying the foundation for what would ultimately become Flitto.
As smartphones rapidly gained global adoption, Lee saw the perfect timing for a mobile, app-based translation service.
In August 2012, he left SK Telecom and founded Flitto with co-founders Jingu Kim and Donghan Kang.
The company name “Flitto” was inspired by the phrase “flit to ~,” meaning “to fly toward.”
[Flitto Deep Dive 2] The First Opportunity We Captured on X
From the very beginning, Flitto drew both attention and high expectations. Shortly after its founding, the company secured early-stage investment from DSC Investment in Korea and was selected for the Techstars London accelerator program, gaining access to global mentorship and networking opportunities.
Yet despite this momentum, the early days of the platform were far from easy.
The core of any crowdsourced translation service is participation, how many people are willing to contribute, and how quickly? If users requesting translations had to wait days for results, or if translators lacked content to engage with, the platform simply could not sustain itself. Securing active participants became an urgent priority.
One of the earliest channels Flitto focused on was Twitter (now X).
Even at the time, K-Pop artists such as PSY and Super Junior were rising as global stars. Fans around the world followed their accounts, but because their posts were written in Korean, most international followers were unable to understand them. In response, fans across different countries began voluntarily translating the artists’ tweets and sharing them within their communities.
From this organic behavior, Flitto’s founding team recognized the potential for a user-driven translation ecosystem.
To support this emerging behavior, the team built a feature that integrated Twitter and Facebook feeds into Flitto and displayed multilingual translations of celebrity posts. The platform initially provided Korean-to-English translations in-house, but users soon began translating these posts into their own native languages, naturally forming a network of “collective intelligence translation.”
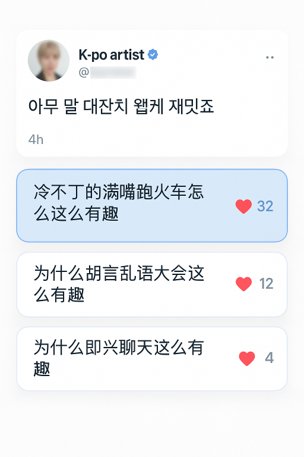
Because translation rarely has a single correct answer, Flitto intentionally designed the system so that multiple users could submit their own versions of the same sentence. Translations with more “likes” appeared higher in the feed, a mechanism that encouraged both collaboration and healthy competition. This structure improved translation quality while simultaneously accumulating a rich diversity of linguistic expressions, enhancing the dataset’s overall value.
The turning point came when PSY directly retweeted Flitto’s service.
This single act triggered explosive platform growth, amplifying translation results across social media and attracting a wave of new users. As participation surged, multilingual translation data accumulated rapidly. These data were then refined through processes such as personal-information removal and error correction, eventually forming high-quality linguistic datasets.
Flitto went a step further by establishing a Human-in-the-Loop quality management system, introducing multi-stage QC performed by professional translators and reviewers. Through this approach, the company achieved over 99% accuracy and ensured that all datasets were fully consented and clean.
Flitto’s Human-in-the-Loop pipeline ensures that every dataset is refined through multi-stage expert verification, producing consistently high-quality, fully consented language data.
With a robust foundation of high-quality data in place, Flitto began to evaluate how effectively this dataset could train real-world AI models, a process that naturally led into the next phase of technological development.
[Flitto Deep Dive 3] From Data to AI Solutions
Flitto began with a clear mission: to build high-quality datasets, fast, cost-effectively, and at scale, for companies and research institutions developing AI models. Unlike today’s common approach of fine-tuning foundation LLMs with task-specific datasets, early model builders often had only the model architecture itself. As a result, they required as much training data as possible.
As we responded to these needs, our internal data volume grew rapidly. To verify whether the datasets we created were truly effective for training, we needed to train our own models and validate performance.
We therefore began tagging our accumulated text datasets with categories such as economics, medicine, law, sports, and travel, and trained models on them. Once a model was capable of automatically predicting tags for newly generated text, human reviewers only needed to validate or correct the model’s first-pass tagging, dramatically reducing the time required for manual classification.
Building on this foundation, we then challenged ourselves to develop a multilingual parallel corpus–based NMT (Neural Machine Translation) system. Today, Flitto’s NMT engine is deployed not only on our website but also in on-premise environments for defense-related and financial institutions, further validating our technological capabilities in AI.
This integrated cycle of data construction → model training → technology validation confirmed a principle we consider fundamental: “AI performance is ultimately determined by data quality.”
This principle became the backbone of Flitto’s product strategy and operational standards.
On this foundation, Flitto has continuously expanded real-time translation solutions tailored to diverse environments. Although each solution addresses different user scenarios, all of them originate from, and evolve through, the same virtuous cycle of Data → Model → Service.
Live Translation (LT)
A real-time simultaneous interpretation solution used in large-scale conferences, forums, and summits, without the need for interpreter booths. LT supports up to 38 languages, providing both text and audio output simultaneously. Participants simply scan a QR code to instantly access translation in their preferred language, enabling immersive, uninterrupted listening experiences.
The LT engine is powered by domain-specific parallel corpora and the CT engine (NMT + STT + contextual inference). Feedback generated onsite continuously flows back into our data pipeline, improving accuracy for proper nouns, intonation, terminology, and culturally nuanced expressions.
Chat Translation (CT)
In 2025, Flitto expanded into digital collaboration with the launch of Chat Translation. The solution supports real-time translation and summarization in up to 37 languages and integrates a hyper-personalization engine that adapts to individual language patterns and document-based knowledge.
One product. Two modes – designed for different communication scenarios.
① Quick Chat (On-the-Go Conversations)
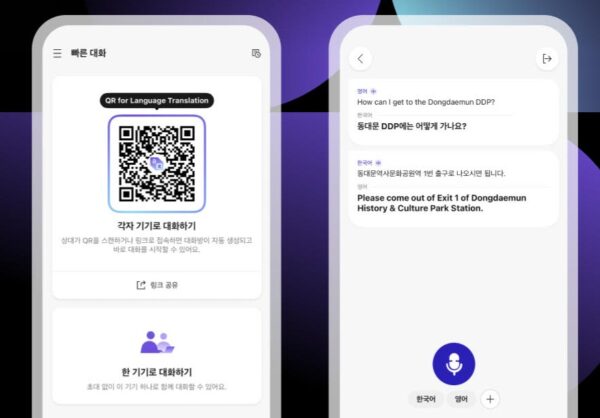
- Designed for travel, business trips, and everyday face-to-face interactions.
- Use a single device for one-on-one conversations, or instantly open a shared chat room by scanning a QR code
- no app download required for the other participant.
- Quick Chat enables fast, natural multilingual conversations anytime, anywhere.
② Online Meeting (Work & Collaboration)
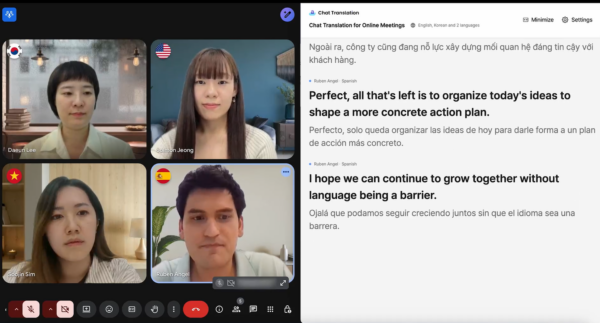
- Built for remote meetings and cross-border collaboration.
- Chat Translation automatically generates meeting summaries, and accurately reflects job-specific terminology.
- By learning from your uploaded documents and materials, it delivers translations that align with your role, context, and professional language
Chat Translation Enterprise (CTE)
Trusted by enterprises and public insitutions, Flitto’s Chat Translation for Enterprise enables secure, domain-specific multilingual communication.
A high-precision translation solution for enterprises, public institutions, banks, tourism, and retail environments. Using a two-device setup, staff and visitors each speak in their native language, and the system automatically translates both sides.
CTE supports:
- Handling multiple simultaneous requests through fixed QR codes
- Domain-specific terminology learning
- Customization based on business documents
Actual real-world speech data, onsite conversation logs, and human-in-the-loop QC reinforce the engine, resulting in continuously strengthened accuracy as usage grows.
Image Translation
An image-based AI translation solution that recognizes text (via OCR) on menus, signs, packages, exhibitions, and more, converting it instantly into multiple languages. Users can simply scan a QR code to access the service. When necessary, clicking on translated elements can surface image-search-based contextual information.
Diverse fonts, lighting conditions, angles, and regional layout variations are incorporated into OCR and translation training, ensuring readability and accuracy across real-world scenarios.
A Continuous Cycle of Data Advancement
Across all software applications, Flitto’s foundation is the ongoing enhancement of data.
By continuously reinjecting real usage data into training—correcting mistranslations, incorporating neologisms, and addressing domain-specific discrepancies—Flitto builds self-evolving AI models whose precision increases the more they are used.
In 2025, Flitto obtained ISO/IEC 27001 certification across all translation solutions, meeting global standards for security and reliability.
This closed-loop cycle, Data → AI Training → Service → Real Usage Logs → Back to Data
, has enabled Flitto to realize a complete, self-reinforcing system. This structure not only advances technological sophistication but also translates into tangible business performance and public-sector expansion.
Business Growth Fueled by Technological Competitiveness
- Flitto has achieved rapid growth over the past several years:
- Revenue increased from KRW 5.7B in 2020 to KRW 20.3B in 2024, achieving a 5-year CAGR of 59.2%.
- Exports expanded from KRW 2.2B in 2020 to USD 8M in 2024, earning consecutive “$1M / $3M / $5M Export Tower Awards.”
- Flitto earned Korea’s first A-grade certification for CoT data quality, filed multiple patents in AI translation, and successfully completed a KOSDAQ listing via the Business Model Special Listing Program in 2019.
- The team has grown from 3 employees in 2012 to over 200 employees in 2025.
[Flitto Deep Dive 4] From AI That Understands Humans to AI That Understands Me
Since its founding in 2012, Flitto has built and operated a platform capable of collecting, refining, and constructing language datasets across text, speech, image, and multimodal formats. While the company initially focused on building relatively simple parallel corpora and single-language speech datasets, it has continuously advanced its platform to meet increasingly complex data needs, ranging from university-level STEM text and long-form translation datasets to speech datasets reflecting dialectal variation and prosodic nuance. This accumulated expertise in data construction has been recognized across both industry and public sectors, forming a core foundation of Flitto’s technological credibility.
The next stage of Flitto’s technological evolution is hyper-personalization. Hyper-personalization refers to an advanced level of AI that provides communication optimized for each individual, capturing a user’s linguistic habits, pronunciation patterns, preferred spellings, stylistic tendencies, and domain-specific knowledge. (Source: How Generative AI Is Driving Hyperpersonalization)

Even a single name can produce multiple legitimate variations, such as:
• LEE JUNG SU
• LEE JEONG SOO
Traditional pattern-based AI systems are unable to interpret these differences as intentional preferences. To address this, Flitto has developed a structure that allows users to directly register or modify their preferred spellings, pronunciations, keywords, and styles as part of their personal dataset. The model references this information as a priority, producing outputs that reflect the user’s linguistic identity and preferences.
This hyper-personalization framework has already been validated through Flitto’s real-time translation services. Words that were previously unrecognized in conference environments or instances of mistranslation are continuously converted into new datasets and reintegrated into the learning pipeline. This iterative improvement process enhances overall STT and NMT performance while simultaneously reinforcing the hyper-personalization engine that adapts to each individual user.
As we move toward the era of AGI, general-purpose models will be required to demonstrate increasingly sophisticated comprehension, reasoning, and contextual transfer. The ability to capture a user’s linguistic rhythm, cultural context, and communicative patterns will become a defining competitive advantage. This is why Flitto positions hyper-personalization not as an optional feature but as a core component of its technological identity, structuring AI systems to evolve from simply “providing correct answers” to “expressing and understanding in the user’s own way.”
Ultimately, language is the most human form of data, an accumulation of culture, emotion, and thought. Flitto views language not as an object of computation but as a foundation for human understanding. Guided by principles of data quality, linguistic diversity, and fairness, Flitto has built a global language infrastructure that ensures consistent communication experiences for users worldwide.
As Physical AI and AGI continue to advance, AI systems will require richer datasets and more complex interaction patterns. With its deep expertise in data construction and its hyper-personalization engine, Flitto is committed to shaping an AI future that is more accurate, more equitable, and more human-centered.
For organizations building multilingual AI systems, language data is a core infrastructure. Flitto continues to invest in high-quality, fully consented, and domain-specific datasets, constructed through human-in-the-loop processes and designed to support real-world AI deployment across industries and regions.
We look forward to collaborating with partners who view language data as a long-term capability and a strategic foundation for sustainable AI innovation.