There was a time when the term Big Data dominated industry conversations. Data was continuously generated from various sources such as web/app services and IoT devices, yet due to limitations in processing large-scale data in real time, much of it was simply discarded.
As technology advanced, it became possible to collect this data in a centralized environment. By analyzing it and extracting insights, services and systems could be improved. While each individual piece of data may seem small, when aggregated, it becomes a powerful asset.
In the era of AI, the importance of data has grown even further. When first designed, an AI model is nothing more than an empty shell with randomly initialized parameters. Through training on datasets composed of input and output data, these parameters are gradually fine-tuned. Only after this learning process is complete does the AI model become fully functional.
Recently, AI models have grown so large that even those with tens of billions of parameters may be considered relatively small. As models increase in size, they require larger and more complex training datasets. This is similar to how academic content evolves from elementary school to middle school, high school, and university as students grow. To efficiently handle large-scale datasets, organizations typically build and operate a Data Warehouse.
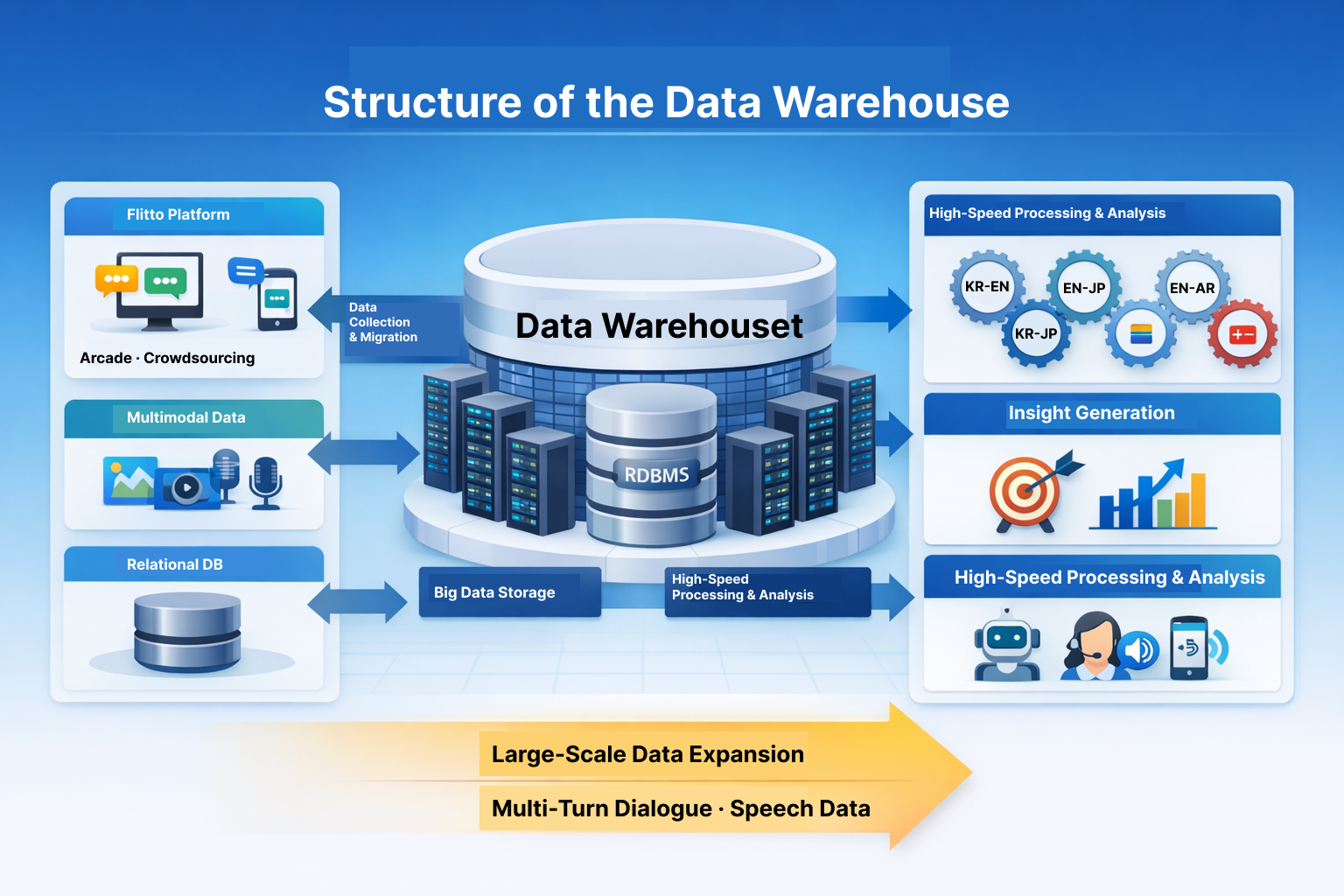
Flitto’s Data Warehouse
Since its establishment in 2012, Flitto has accumulated multilingual parallel corpora generated by users on its platform.
In the early stages, a relational database management system (RDBMS) was sufficient for storing this data. However, as the volume increased, search speeds declined. Additionally, managing not only parallel corpora but also multi-turn dialogue, image, and audio data, multimodal datasets, revealed the limitations of RDBMS systems.
After reviewing various solutions, Flitto selected a new system. Existing data was migrated accordingly, and newly generated data is now directly stored in the Data Warehouse.
Similar to Big Data systems that collect large volumes of data and analyze them to uncover insights, Flitto’s Data Warehouse stores only the data required for dataset construction. Based on this foundation, new data is generated and expanded continuously.
Expansion of Parallel Corpora
Discover Flitto’s Multilingual Parallel Corpora👇
Parallel corpora are essential for enabling AI models to understand and translate multiple languages. In recent years, machine translation performance has improved significantly. Support has expanded beyond major languages to include Arabic dialects used in the Middle East and North Africa, as well as regional minority languages in China and India.
Initially, a Korean sentence was translated into English to create a Korean–English parallel corpus.
- Korean: 오늘 날씨는 매우 좋습니다.
- English: The weather is very nice today.
Based on this parallel corpus, someone who knows Korean or English can translate the sentence into Japanese.
- Korean: 오늘 날씨는 매우 좋습니다.
- English: The weather is very nice today.
- Japanese: 今日はとても天気がいいです。
By simply adding the Japanese translation, three parallel corpora are created: Korean–English, Korean–Japanese, and English–Japanese.
What if someone who speaks Estonian translates the English sentence into Estonian?
- Korean: 오늘 날씨는 매우 좋습니다.
- English: The weather is very nice today.
- Japanese: 今日はとても天気がいいです。
- Estonian: Täna on ilm väga hea.
There are not many people who speak both Korean and Estonian. If we needed to rapidly build a large Korean–Estonian parallel corpus, the task might seem overwhelming.
However, by extracting sentences requiring multilingual translation from the Data Warehouse and registering them on Flitto’s crowdsourcing platform, Arcade, translated and reviewed sentences can be re-stored in the Data Warehouse. This enables the expansion of multilingual parallel corpora without significant difficulty. In other words, even without a direct Korean–Estonian bilingual speaker, it becomes possible to build a Korean–Estonian parallel corpus.
However, there is an important consideration when expanding data in this manner. What happens when a sentence that has already been translated into one language is translated again into another language, especially if it contains proper nouns?
The previous example works well in everyday conversation across languages. But consider the following sentence:
- Korean: 외국인들의 여행 스타일이 바뀌면서 최근에는 성수동이나 홍대입구 등이 핫플레이스로 떠오르고 있습니다.
- English: As foreign travelers’ travel styles have changed, areas such as Seongsu-dong and around Hongdae have recently emerged as popular hot spots.
Now let us translate the English sentence into Chinese and Estonian:
- Chinese: 随着外国游客旅行方式的改变,圣水洞和弘大周边等地区最近已成为热门打卡地。
- Estonian: Kuna väliskülastajate reisimisstiil on muutunud, on sellised piirkonnad nagu Seongsu-dong ja Hongdae ümbrus viimasel ajal kujunenud populaarseteks tõmbekohtadeks.
When viewing the resulting Chinese–Estonian parallel corpus, Chinese readers may not know where Seongsu-dong or Hongdae are located, and Estonian readers may even assume these are places in China.
Although both sentences are grammatically correct, they may not align well with the social or cultural contexts of China or Estonia. While such data can still be used for AI model training, it may not represent the most semantically optimal parallel corpus.
Therefore, the Data Warehouse must manage such cases with careful consideration.
Data Warehouse for AI Training
By storing all data generated through Flitto’s services in the Data Warehouse, each dataset can be utilized to create new datasets. Through repeated iterations of this process, large-scale datasets can be constructed.
In the next article, we will explore how Flitto has expanded beyond parallel corpora to include multi-turn dialogue and speech data.