
Part 3 of the ACL 2023 Review Series for NLP research papers on recent findings and suggestions
The 61st Annual Meeting of the Association for Computational Linguistics (ACL 2023) showcased numerous astounding NLP research papers during the first half of this year. For the first two sessions, we looked at some recognized papers and ones that reflect where the technology stands today.
Concluding the series, Flitto DataLab highlights some NLP research papers that have particularly caught our interest. These studies offer an innovative standpoint on where the technology can head next.
Causes and Cures for Interference in Multilingual Translation
Uri Shaham, Maha Elbayad, Vedanuj Goswami, Omer Levy and Shruti Bhosale
This research poses a direct implication to any language translation service.
In his opening, presenter Uri Shaham stated how multilingual interference models can benefit from the synergy or suffer from interference between language pairs. For example, an MT model trained to translate English to Finnish may witness better performance in Estonian but negatively impact Chinese translation.
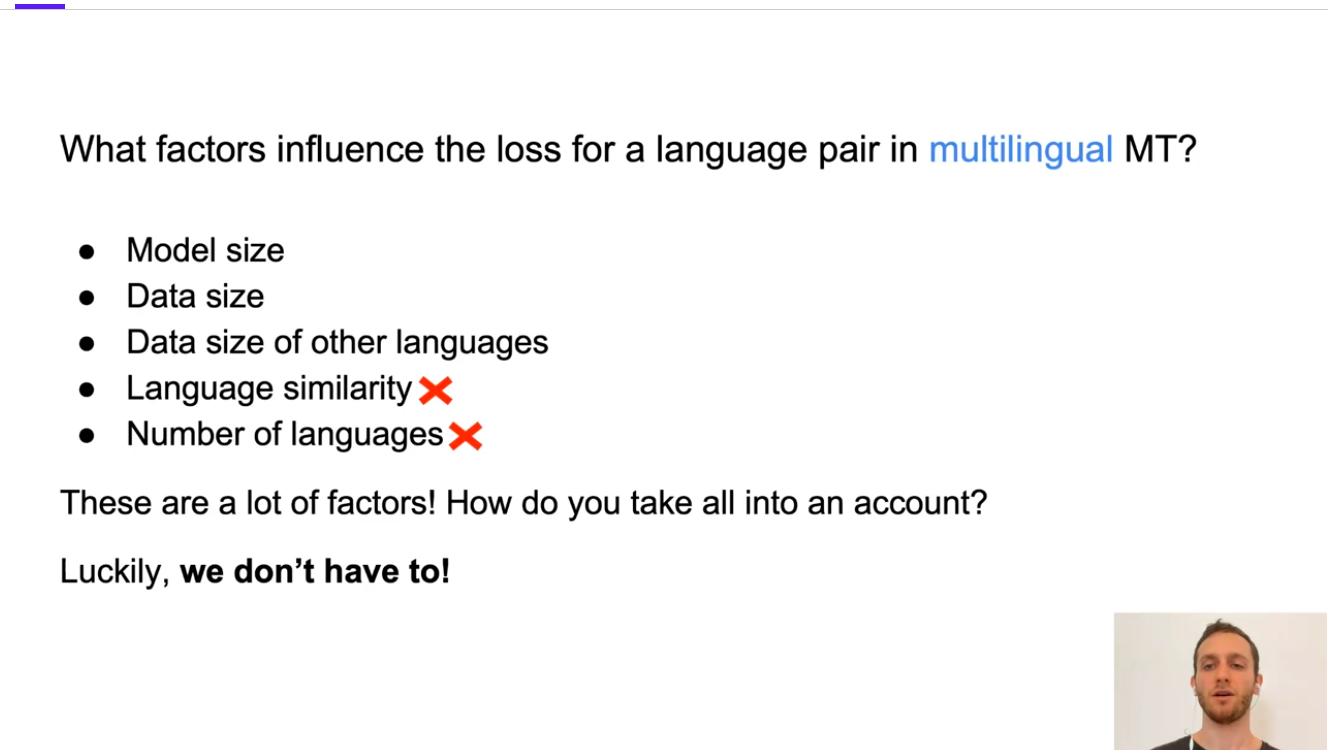
Shaham led his team to examine major factors aggravating interference in multilingual translation and mitigation strategies. They found that language similarity and the number of languages are not major contributors to the model’s loss. This leaves model size, data size, and the size of datasets of other languages in the equation for improving MT’s performance.

For this NLP research paper, Shaham experimented with four transformer variants to support their hypothesis, each bearing different sizes and parameters. Then, they trained the models with linguistic datasets consisting of 15 languages before measuring performance loss between the source and target interference language.
They reported only a slight performance difference between English -> French and English -> Russian when training the model with 15.2 million English-Spanish samples. The result showed that the level of similarity between languages were not the decisive factor for interference.
Meanwhile, data size, model size and parameter poverty tended to cause severe interference. They also found that the smallest model performed poorly because of the limited parameter counts. Shaham recommended increasing the sampling rate to minimize interference loss, mainly when training with a low-resource language.
Towards Speech Dialogue Translation Mediating Speakers of Different Languages
Shuichiro Shimizu, Chenhui Chu, Sheng Li and Sadao Kurohashi
Shuichiro Shimizu drew our attention to multilingual speech dialogue translation (SDT), an NLP discipline less developed than monologue translation.
Speech dialogue translation (SDT) applies automatic speech recognition and machine translation to enable listeners to comprehend speech in their native language. For example, an audio translator software incorporating SDT will enable someone to say “Konnichiwa” and let another person read “Hello,” its English translation.
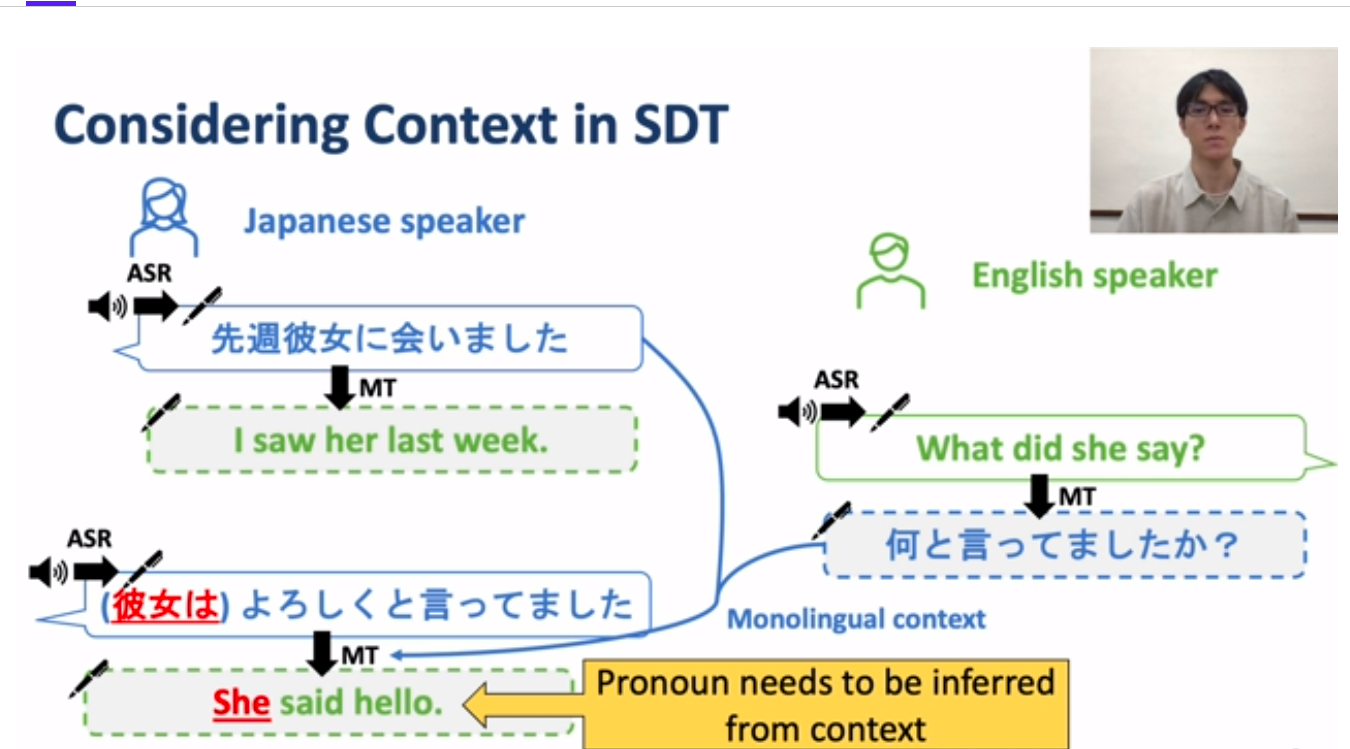
To support further developments in this discipline, Shuichiro and his fellow researchers created the SpeechBSD dataset. They curated crowdsourced audio from different platforms, taking both monolingual and bilingual contexts into consideration.

Shuichiro highlighted the importance of the model’s ability to infer the speaker’s pronouns from the spoken dialogue. Subsequent experiments confirmed that applying bilingual context in the dataset improves the model’s performance when translating speech dialogue.
Towards Understanding Omission in Dialogue Summarization
Yicheng Zou, Kaitao Song, Xu Tan, Zhongkai Fu, Qi Zhang, Dongsheng Li and Tao Gui
Pre-trained large language models play an increasingly important role in summarizing dialogue. Dialogue summarization aims to extract essential information in customer service, medical consultation, meetings, and other use cases. However, such models occasionally omit specific facts, leading to inaccurate summaries. This limits their practicality in real-life applications.

Researcher Yicheng Zou, in his presentation, highlighted the lack of efforts to address omission issues affecting language models. He compared several models across five domains to gain insight into the severity of the problem. He noted that even established models like BART experience substantial omission issues.
Zou proposed a specific task to enable a model to identify and overcome omissions. Here, the model is presented with several candidate summaries, where it needs to predict which key information is omitted. With this principle, the researcher created OLDS, a high-quality annotated dataset that trains a model to detect omission.

OLDS was constructed with summaries of datasets from different domains. It consists of candidate summaries generated by different language models. Then, Zou tested the dataset with BERT and RoBERTa on several baseline tasks, including text matching, extractive summarization, and question answering. The results reaffirm Zou’s hypothesis that large language models might omit key points when summarizing. But the speaker further revealed that refining the model with omitted content can improve its performance.
Annotating and Detecting Fine-grained Factual Errors for Dialogue Summarization
Rongxin Zhu, Jianzhong Qi and Jey Han Lau
In this session, Ph.D. student Rongxin Zhu shed light on the complexities of dialogue summarization. In his paper, he discussed summarization models’ challenges in detecting fine-grained factual errors. Such occurrences lead the model to misrepresent or fabricate facts from source conversations.
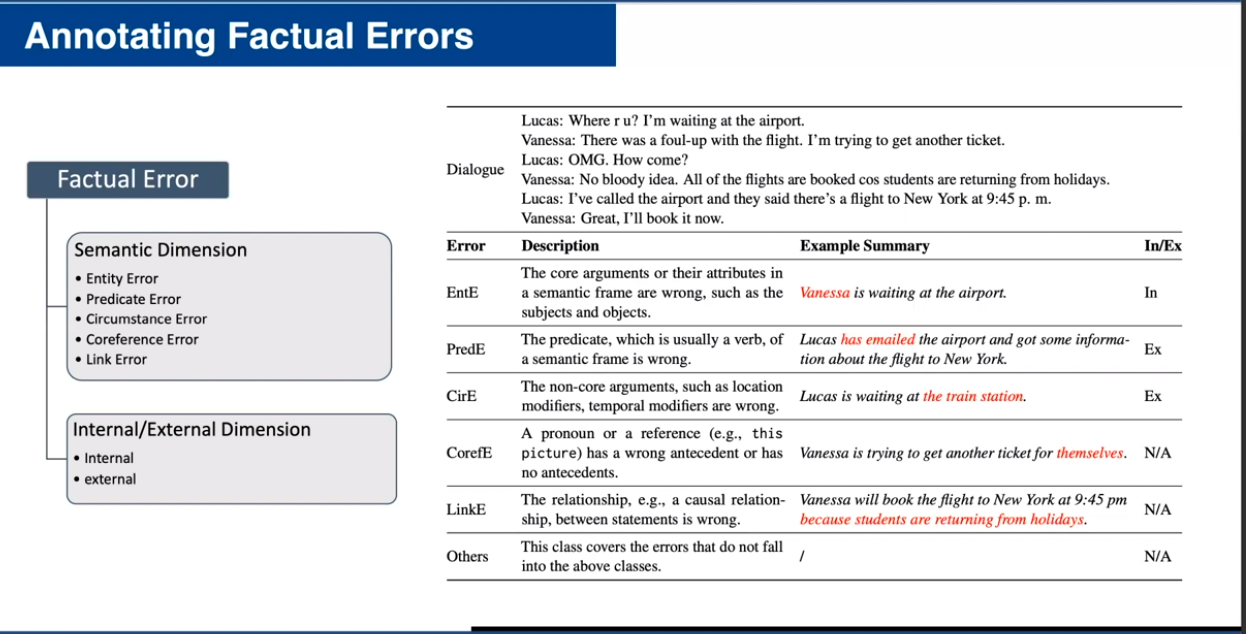
According to the speaker, there is a lack of datasets that could effectively benchmark a model’s ability to detect factual errors in dialogue. Specifically, Zhu pointed out that current datasets cannot answer pressing questions, such as:
- Where the error appears
- Why the error exists
- What the types of errors are
To support better factual error analysis in summarization models, the speaker’s team developed DiaSumFact. DiaSumFact is an annotated representation of various fine-grained factual errors, including entity, predicate, and circumstance errors. Then, they tested several models with the dataset, revealing questionable performance that produces intrinsic and extrinsic factual errors.
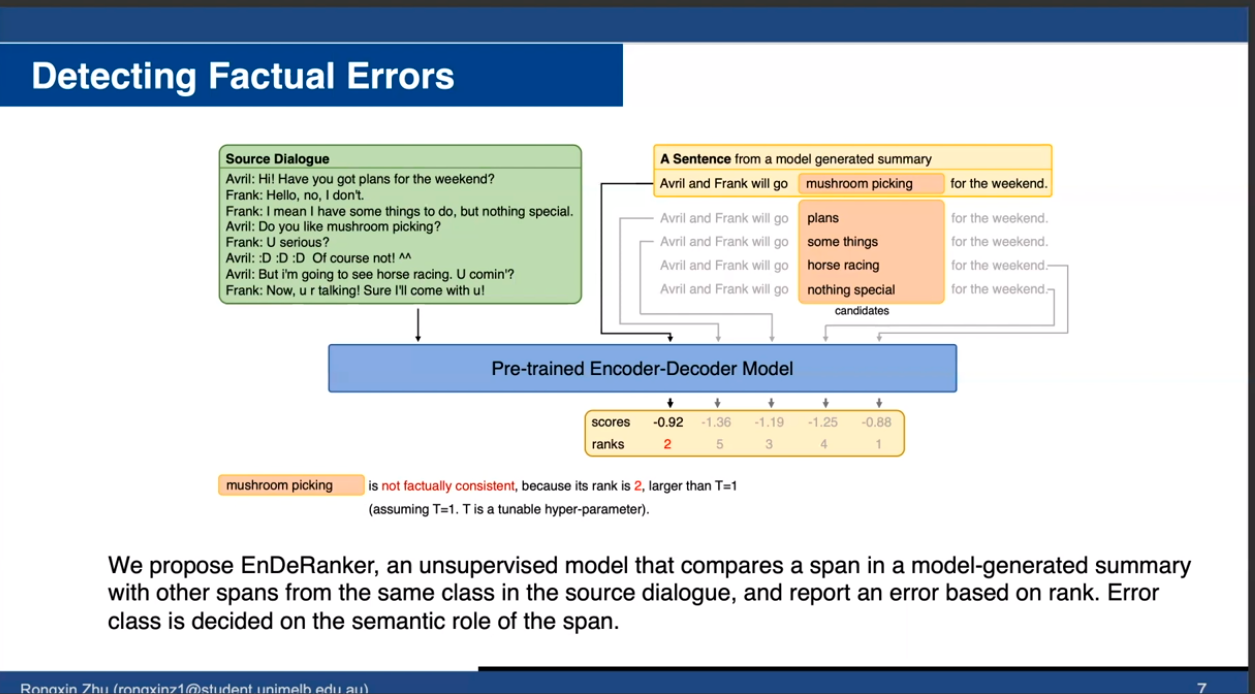
The speaker also proposed EnDeRanker, an encoder-decoder model that scores and ranks spans of probable error to enable better prediction. It shows comparable performance against two state-of-the-art models that excel in detecting entity errors. Yet, all models have major room for improvement as none demonstrated significantly impressive performance across all tasks.
Wrapping up in NLP research papers of 2023 so far…
ACL 2023 revealed remarkable insights and advancements on the NLP research landscape of 2023 that continue to shape the future of language technology.
As we wrap up our exploration of these notable research papers, it’s clear that the field is evolving at an unprecedented pace. We’re excited for more exciting possibilities to be enabled by these AI-driven language understanding and communication. Upon further progress, technologies like speech dialogue translation will truly revolutionize the field.
Stay tuned as we bring you further updates on the ever-evolving realm of NLP innovation.