
Part 2 of the ACL 2023 Review Series on the in-depth analysis on the state of NLP today
Many aspects of natural language processing (NLP) technology continue to evolve at a fast pace.
However, some benchmarks are just harder to overcome. There are areas of improvement detectable from a non-technical users’ standpoint. For instance, many models struggle with issues of trustworthiness or diversity.
To improve something, we must first know where and what to improve. That is why in this session, Flitto DataLab has listed some of the notable research papers presented during the 61st Annual Meeting of the Computational Linguistics (ACL 2023) that precisely pinpoint what these problems are.
ORCA: A Challenging Benchmark for Arabic Language Understanding
AbdelRahim Elmadany, ElMoatez Billah Nagoudi and Muhammad Abdul-Mageed
Despite advancements in natural linguistic processing, there is a lack of publicly-available benchmarks for evaluating a model’s capability in understanding Arabic languages. To complicate the matter, Arabic is a collection of several languages native to different regions.
In this presentation, AbdelRahim Elmadany introduced ORCA, a benchmark to evaluate the model’s performance across several linguistic tasks for the Arabic language.
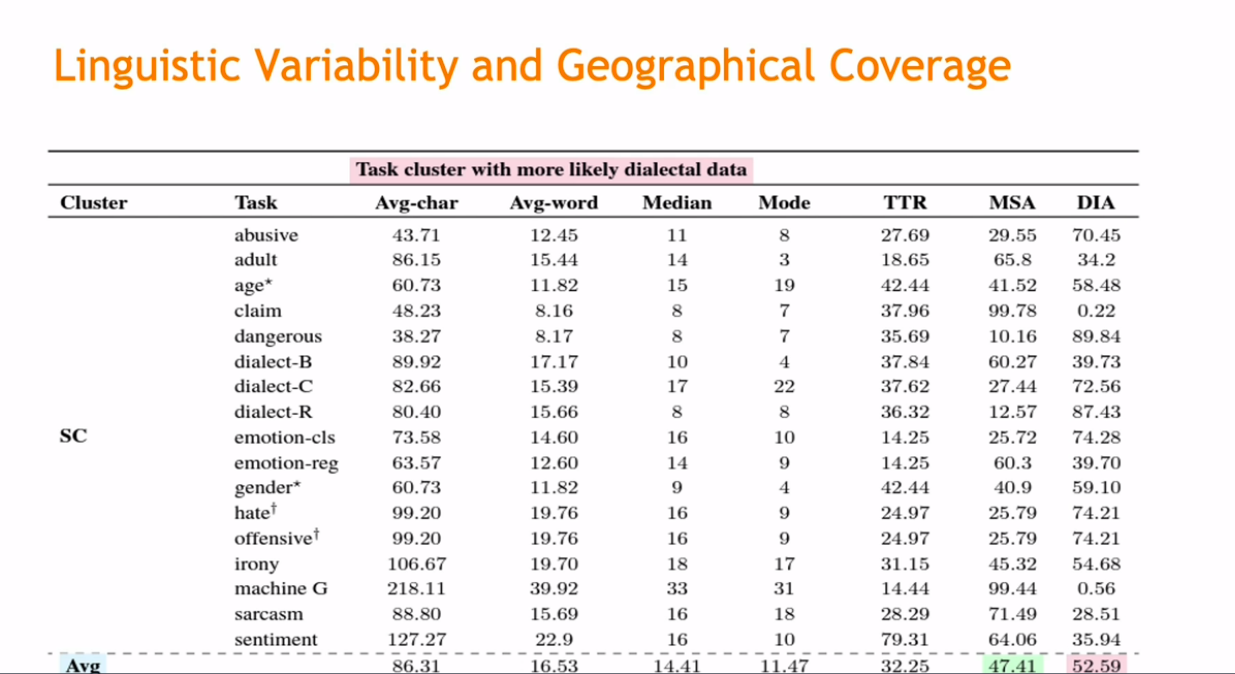
ORCA is a comprehensive suite of training samples derived from 60 datasets. It was developed to enable 7 Arabic NLU tasks, including sentence classification, structured prediction, and topic classification. These task clusters were carefully designed to encompass specific variables. For example, sentence classification includes datasets that identify sarcasm, offensive, abusive, and dialect-variants in the Arabic language.
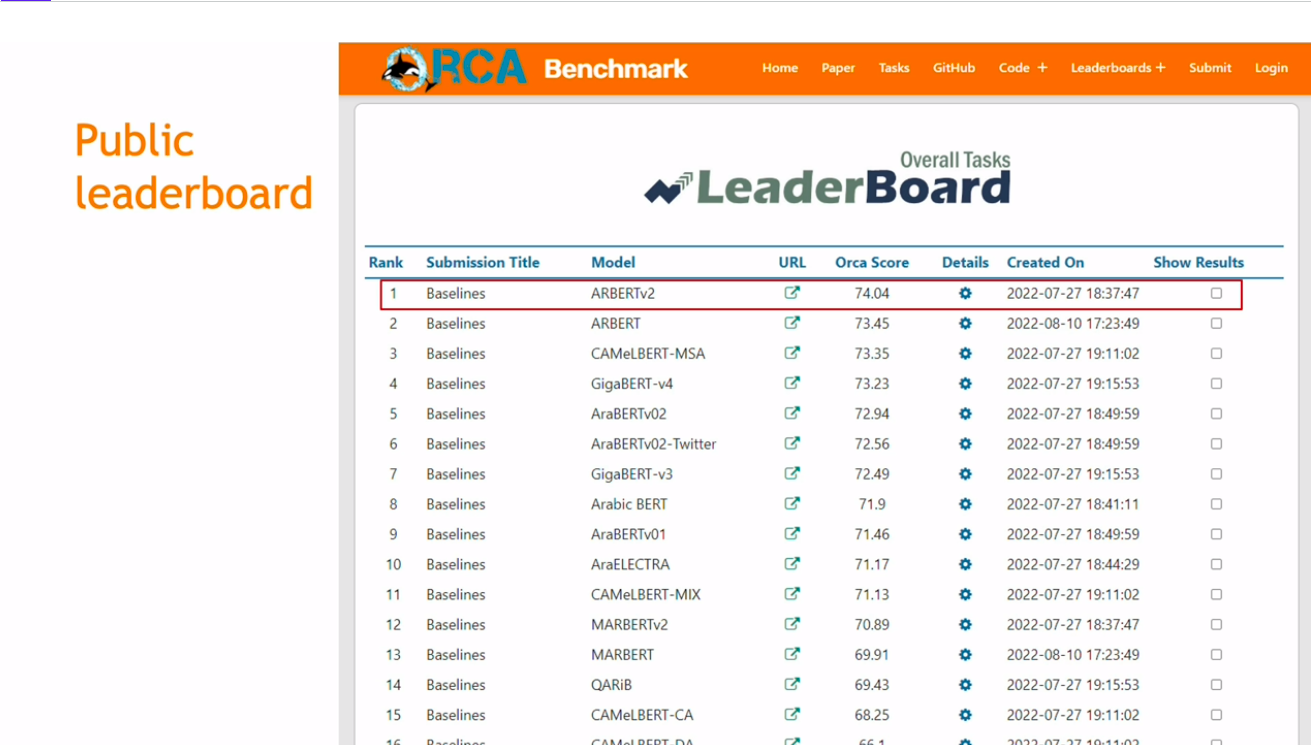
AbdelRahim’s team evaluated ORCA with 16 models capable of understanding the Arabic language. The MARBERT V2, for example, performed exceptionally well in datasets derived from social media. They mapped the ORCA score of respective models and listed their performance in a publicly available leaderboard, enabling future research.
NLP today underrepresents languages like Arabic
Arabic is one of the most commonly used languages in the world. Meanwhile, today’s NLP technology lacked the capability to duly represent the language. With this comprehensive benchmark, we can look forward to more advancements when it comes to NLU capacities in the Arabic language.
Harmful Language Datasets: An Assessment of Robustness
Katerina Korre, Ian Androutsopoulos, Alberto Barrón-Cedeño, Lucas Dixon, Léo Laugier, John Pavlopoulos, Jeffrey Sorensen
This section covers a session of the workshop on online abuse and harms. Here, notable faculty members, researchers, and engineers demonstrated how to build a harmful language detector. In addition, they discussed the intrinsically difficult nature of achieving robustness in assessments.
Data scientists fine-tune a language model to detect and prohibit harmful language. They use annotated datasets consisting of descriptive labels of what constitutes harmful language.
Katerina Korre and her fellow speakers presented the consistency of such datasets when applied across different domains.
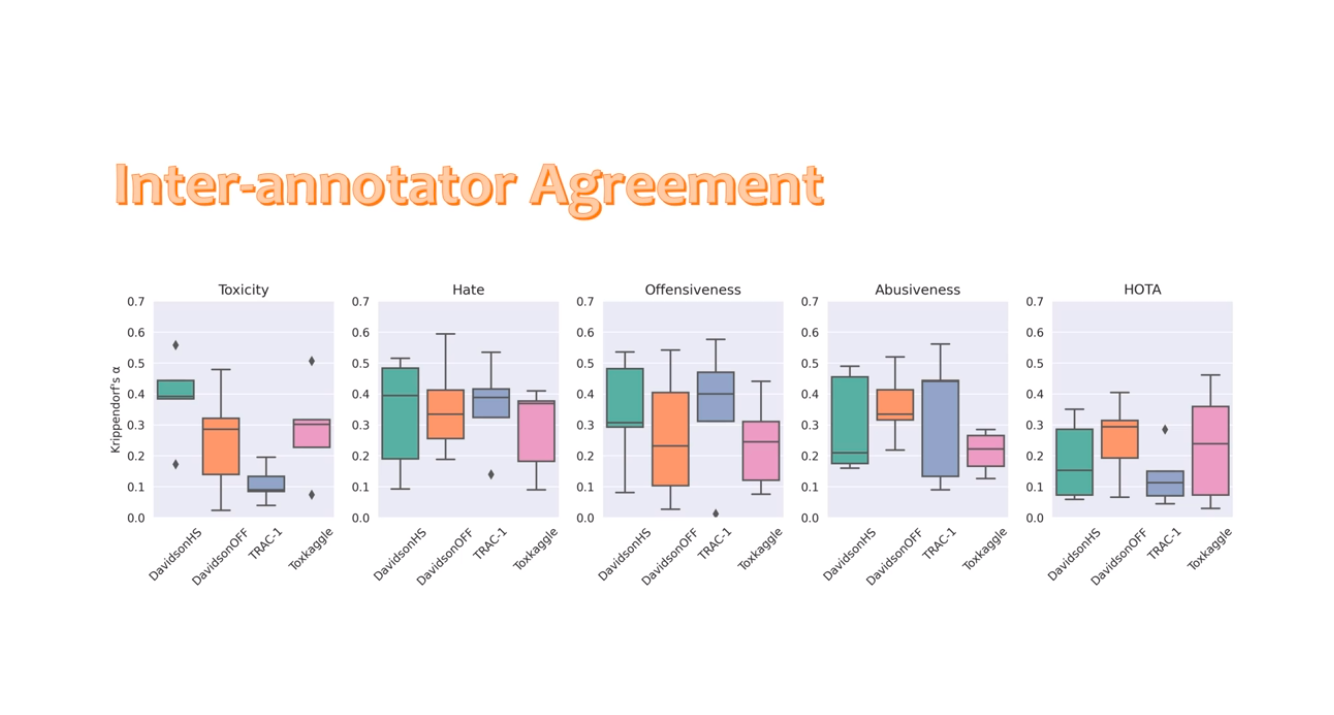
Katerina first investigated whether human annotators can remain consistent, despite the subjective nature of detecting harmful elements in linguistic sources. The researchers curated several batches of datasets, including Davidson, TRAC, and Toxkaggle. Each batch consisted of equal instances, where they selected 80 test questions for re-annotation. Labelers were tasked to label the questions as toxic, abusive, offensive, hateful, and HOTA (hateful languages encompassing all aspects).
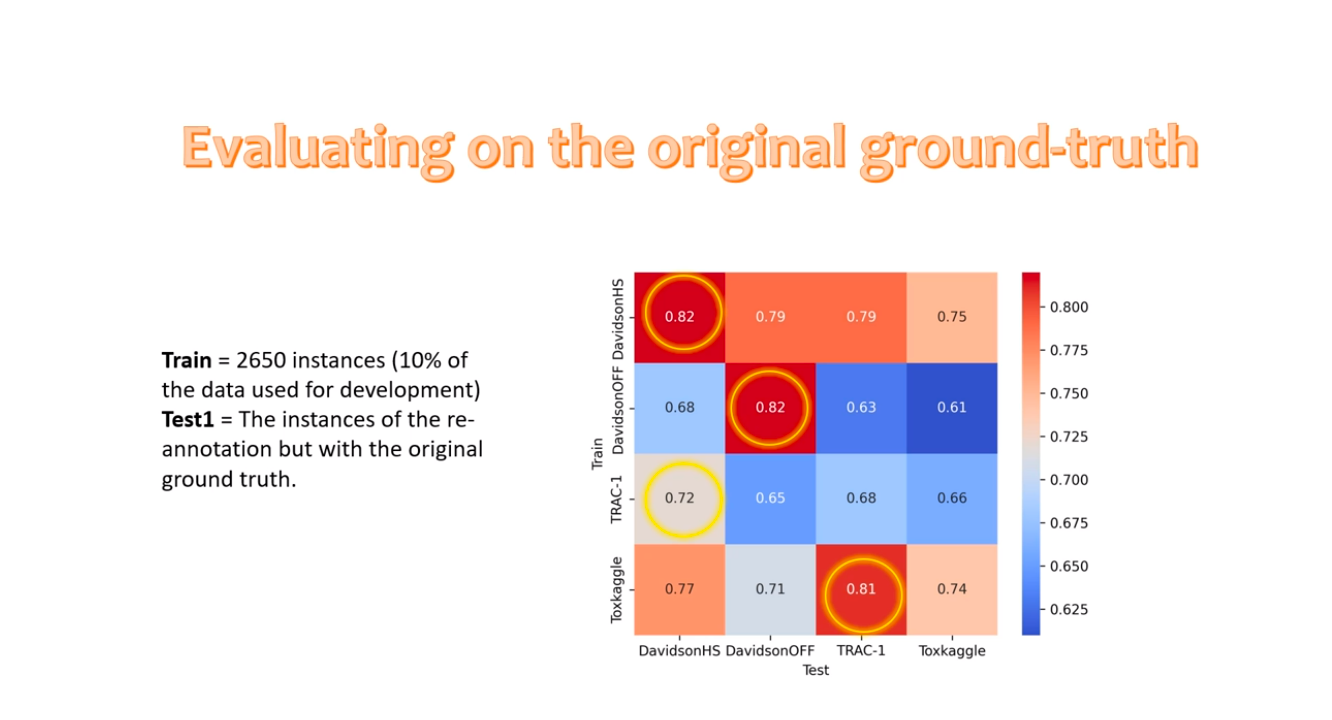
In her experiment, Katerina found a lack of inconsistencies and agreement among annotators for all datasets, indicating mounting challenges in hateful language classification. They then trained the models with the annotated instances to evaluate their capability to generalize across different datasets. While models might perform better in detecting harmful content from the same data source they train on, there are exceptions where models perform better on new data.
Ultimately, the study indicated that broader terms like toxicity and HOTA tend to have more consistent definitions than others. Moreover, it confirmed the previous findings that we can get higher accuracy by assessing on data from the same source as the training set rather than from a different source, although it doesn’t always warrant better results.
What is the Real Intention behind this Question? Dataset Collection and Intention Classification
Maryam Sadat Mirzaei, Kourosh Meshgi and Satoshi Sekine
Large language models (LLMs) have been instrumental in enabling question-answering chatbots. However, can the underlying neural network perceive the intention of asking a particular question? Maryam Sadat Mirzaei and her team gave an interesting take on this problem.

In this presentation, Maryam laid out several negative and positive intentions an individual might harbor when asking a question. She described the complex process of thoughts, reasoning, and interpretation experienced by the answering party. While some studies focus on positive and neutral sentiments of questions, none exist to investigate a model’s capability to perceive negative intentions.
Therefore, Maryam’s team developed a dataset mainly from conversations on Wikipedia. Through interactive studies, they divided negative intentions into several categories, including manipulation, judgmental, hostility, and to embarrass. They tasked the annotators to label the question according to the perceived intention polarity and category.
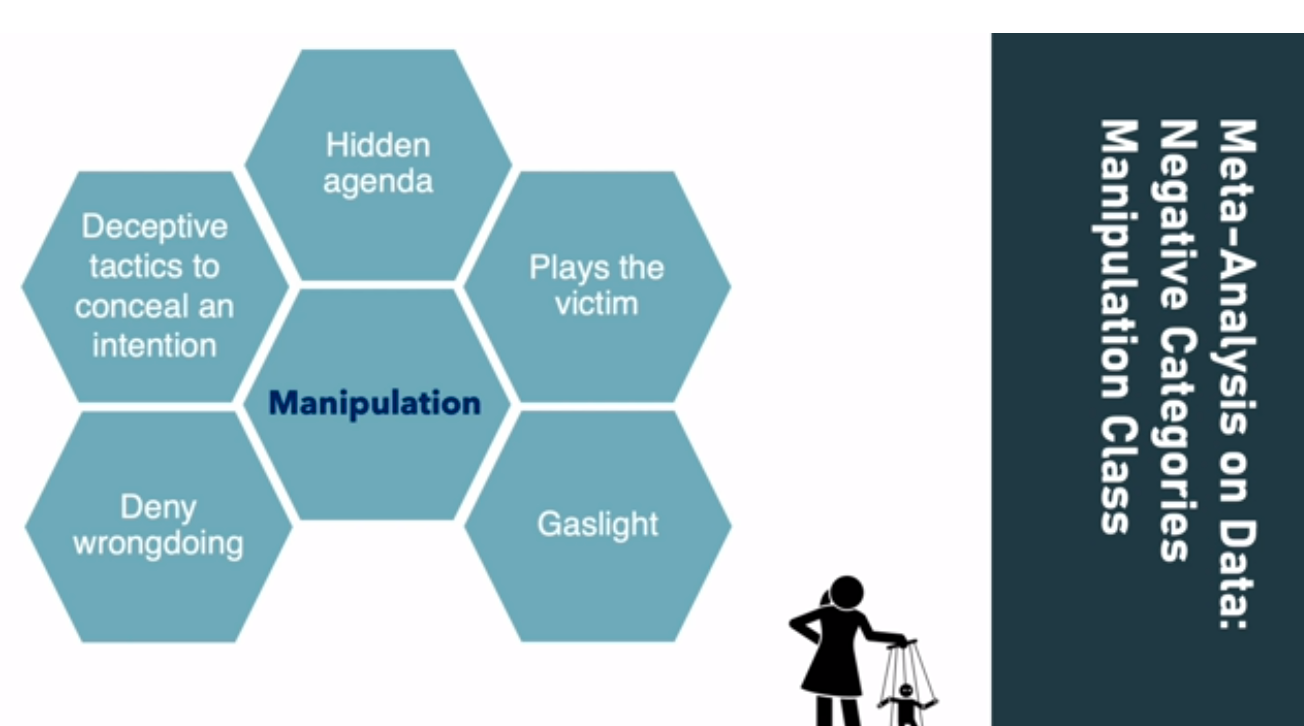
During the process, the researchers discovered various factors that might complicate annotators’ efforts. For example, elements of manipulation, such as gas light, playing the victim, and having a hidden agenda, can be hard to detect. Moreover, a reader’s varying perspective and tolerance threshold also affect what qualifies as negative intentions.
When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories
Alex Troy Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi and Hannaneh Hajishirzi
It’s insufficient for us to depend solely on NLP today. Large language models are a notable example, as they’re known to be unreliable fact-checkers. Alex Mallen and his fellow researchers shed light on the cause of such a phenomenon.
According to his team, language models tend to encode more popular facts into their parameters. However, such models hallucinate when prompted with the knowledge they didn’t memorize.
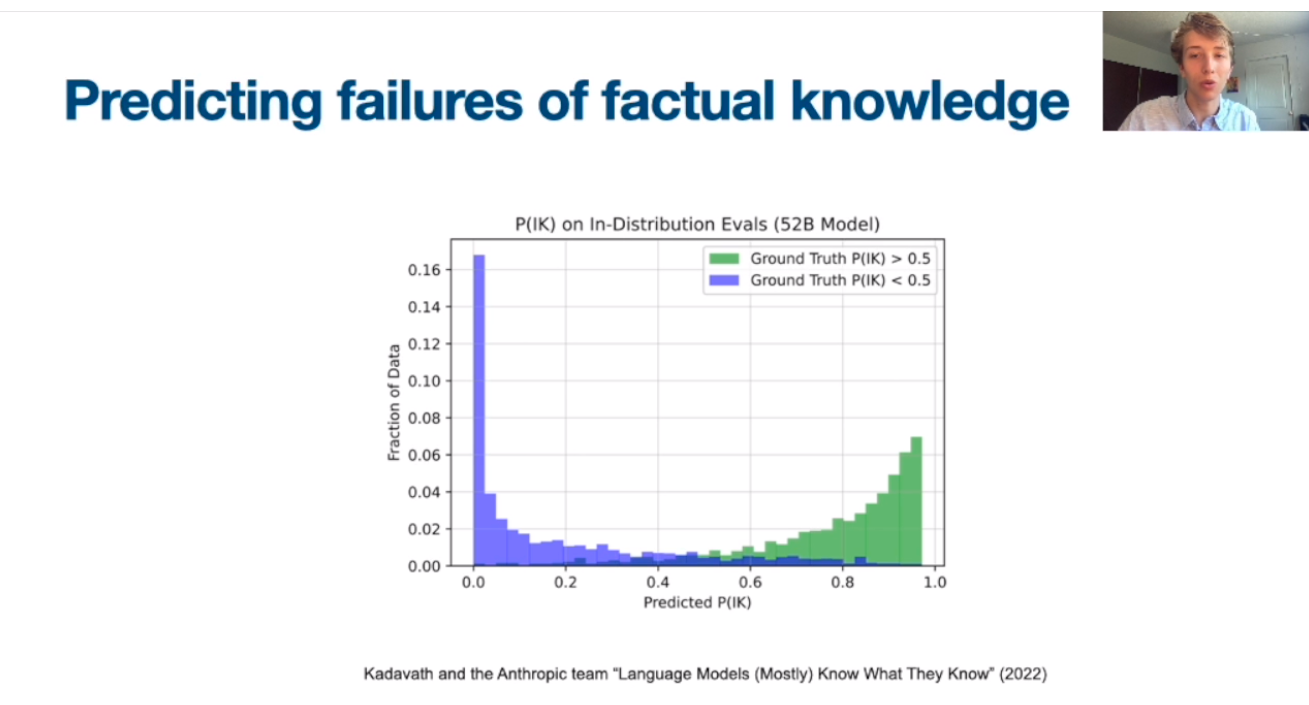
Alex theorized that the model would only remember considerably popular facts. To support the hypothesis, his team developed a PopQA dataset, which associates subjects in the question-answer pair to their popularity. They tested the dataset with several models and confirmed the correlation between factual accuracy and popularity.
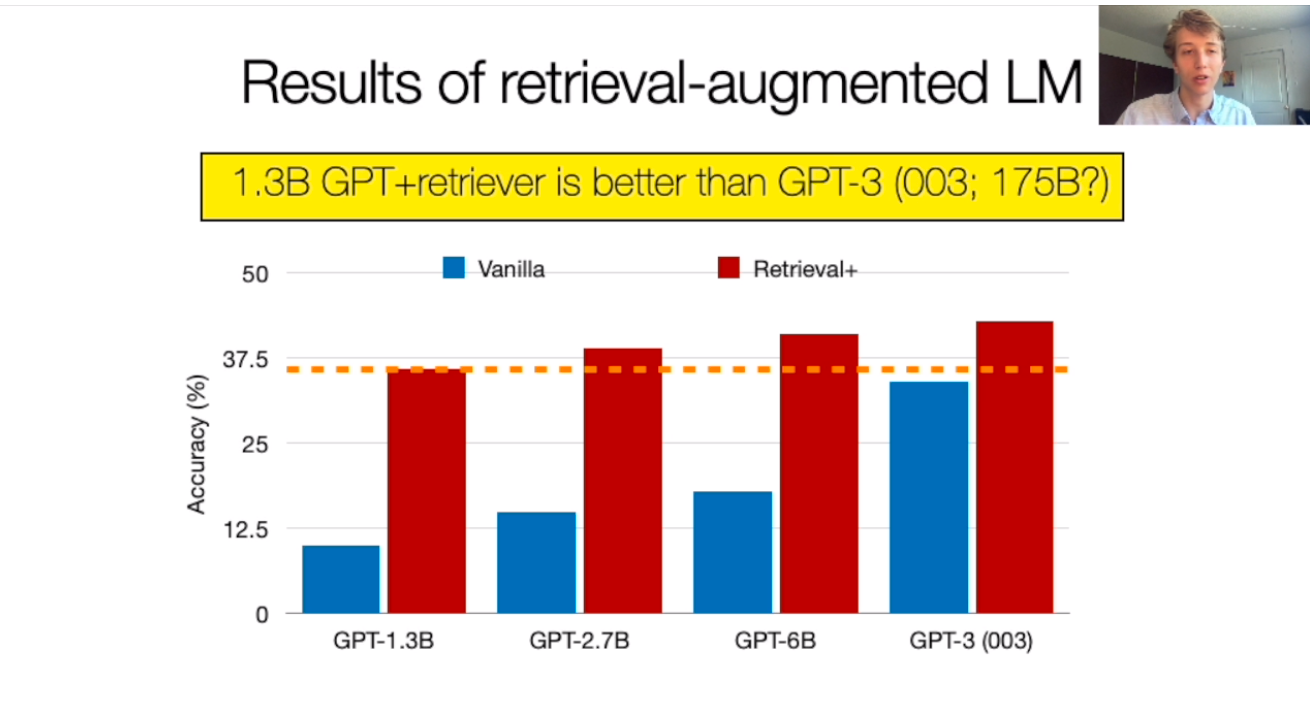
The researcher then sought ways to overcome the issue. Apparently, scaling the model proved futile, as models would only expand their parametric memory for popular facts.
Instead, the researchers discovered that augmenting the language model with a retrieval mechanism improves its factual accuracy. For example, integrating a 1.3B GPT with a retrieval mechanism bore better performance than a pre-trained GPT-3.
What’s the Meaning of Superhuman Performance in Today’s NLU?
Simone Tedeschi, Johan Bos, Thierry Declerck, Jan Hajiˇc, Daniel Hershcovich, Eduard H Hovy, Alexander Koller, Simon Krek, Steven Schockaert, Rico Sennrich, Ekaterina Shutova and Roberto Navigli
Simone Tedeschi and his co-researchers made several arguments to debunk claims that the applications of NLP today have outperformed humans in specific tasks.
While large language models may exceed human capabilities in simple procedural tasks, they might not fare well in applications that require specific knowledge and inference.

The speaker cited several unfair comparisons when models are pitted with popular human benchmarks like SuperGLUE and SQuaD.
First, he noted that humans are evaluated by only a fraction of test sets compared to language models. Next, he drew our attention to the questionable quality of ground truth data used in such evaluations.

Even the enrollment of human annotators in developing the comparison benchmarks is flawed in several aspects. Simone opined that comparing the score of the best annotators rather than using the average score charted by humans is more viable.
Moreover, the pay rate to engage a human annotator varies, which can lead to low motivation and inconsistent results in different benchmarking tasks. Language models may be smart, but the abovementioned factors make it unfair for human capabilities to be compared to NLP today.
How much do language models copy from their training data? Evaluating linguistic novelty in text generation using RAVEN
Tom McCoy, Paul Smolensky, Tal Linzen, Jianfeng Gao and Asli Celikyilmaz
Large language models can produce lengthy text that sounds coherent, but are they truly unique?
Coherence might sometimes be inherited from an author’s work, which the model copies into the result. Tom McCoy published a paper investigating GPT-2’s susceptibility to producing exact copies of its training data. In this research, Tom examines n-gram and syntactic novelty.
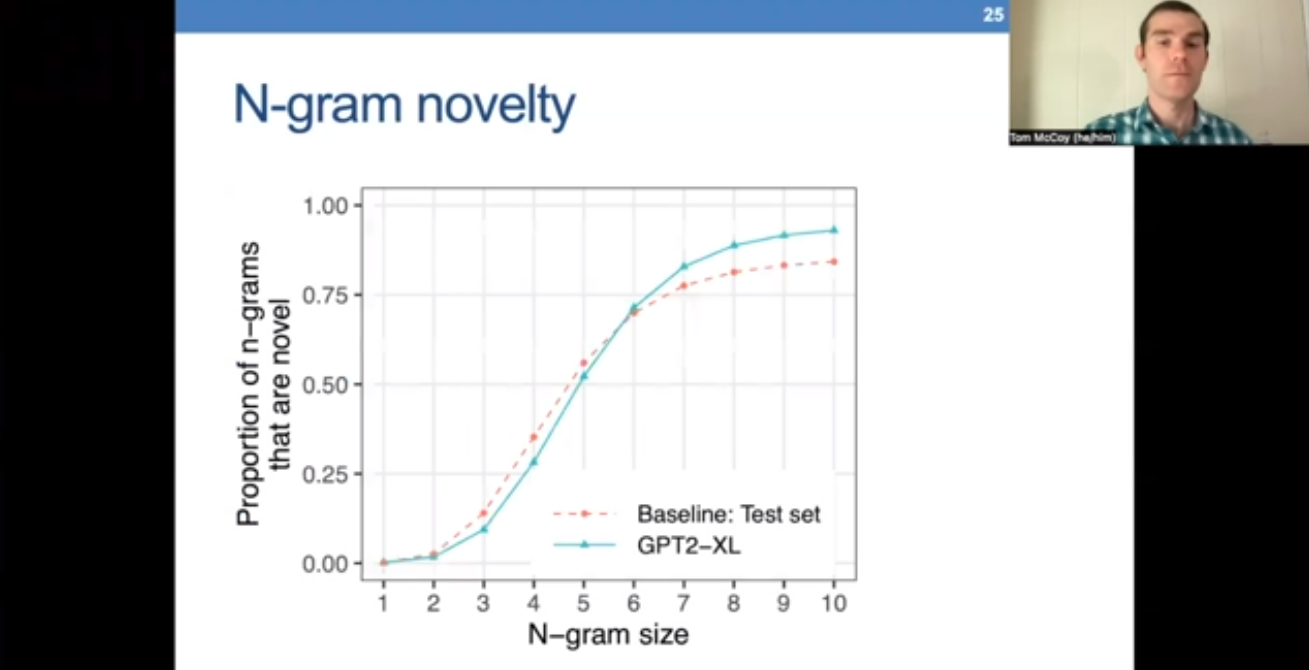
The author found that GPT-2 will most likely generate novel N-Grams, particularly for N size 5 or larger. Likewise, the model exhibits similar results for syntactic novelty – with a higher probabilistic for originality when the dependency path goes beyond 5.
Overall, language models will produce novel text in most situations, but they are occasionally prone to copying.
Wrapping up on what’s happening in NLP today…
In the previous session, we covered some of the well-known papers presented during ACL 2023.
Many of the research papers in this article also received awards and recognition, but that’s not the sole reason why we’ve chose to cover them. These studies are highly relevant in understanding the capabilities and state of NLP today. They give us a sense of direction where to head next in order to make the technology more responsible for everyone.
In the last chapter of the ACL 2023 series, we’ll talk about where to move next. The select papers covered in the next session will suggest a keen insight on the possible methodologies we can take. Stay tuned!