
Large language models (LLMs) are not a new concept. Numerous tech companies have been developing their own LLMs even before the superficial success of ChatGPT and other generative AI applications. Over years, the neural giants saw remarkable advancements, especially when it comes to their mechanisms. Generative AI applications that utilize LLMs also display stunning versatility today.
Different LLMs each have distinct characteristics. While their compositions, performance, and sizes may vary when it comes to supported languages or data sizes, they have a common goal, which is to offer values to their end-users.
Meanwhile, not a single LLM provides a one-for-all solution to all end-user needs. An ongoing problem for generative AIs available so far is their unreliability despite the seeming cleverness.
If so, is it possible to achieve a foundational LLM that covers both accurate and creative generative AI applications? And how can we achieve it?
First, what is a large language model?
A large language model (LLM) refers to a massive structure of language data that runs on a specific algorithm (model) that enables it to process, predict, and generate text. Each company has its own unique recipes to their own model.
The number of parameters are often used to define the performance of LLMs. The parameter refers to the value in which the model can diversify its output and process inputs more efficiently. The amount of parameters is considered to be proportional to the size of the text data LLMs are trained on. The bigger the text dataset, the higher the parameters the models are able to process.
Some LLMs, in order to scale these parameters to train on, utilize massive information as their initial unsupervised training dataset. For instance, these datasets could have been scraped from the internet. LLMs trained this way can produce human-like output solely by the sheer amount of human-generated text they’ve learned.
Bigger LLMs are not synonymous to better LLMs
Not all information available in the world wide web is factual or informative. As goes the popular saying in the field of machine learning, “garbage in, garbage out,” the above-mentioned training method is in part what also limits the model. The resulting model is also left with parameters that contain biased, harmful, or completely wrong information that can be detrimental to the end-user experiences.
To counter this, LLMs can be modified and trained for specific use cases through fine-tuning. The popularized ChatGPT is one such example. It was trained with a supervised fine-tuning method called Reinforcement Learning from Human Feedback, or RLHF. This process involves human teachers who assess, score, and correct the model so that it can answer better next time.
However, fine-tuning is a relatively superficial procedure. It’s another question whether it can completely block out unhelpful answers rooted in the foundational composition of the model.
Use cases for “creative” text generation via LLMs
One of the biggest assets for LLMs trained on massive text datasets is their capacity to produce natural results. These LLMs can be used to build “creative” generative AI tools that end-users can utilize for broad domains that do not require much fact-checking.
Some of possible generative AI applications via these massive and creative LLMs include:
- Inspiration for users who seek casual informative references to kickstart their intended activities
- Companionship for users who are looking for someone to talk to
- Efficiency for users who want to process long blocks of information into more digestible versions
- Entertainment for users who are fascinated by the concept of AIs in general
One LLM can serve multiple user groups through fine-tuned generative AI models. These end-users can be artists, computer scientists, marketers, educators, and more.
We can’t fully rely on LLMs due to issues like hallucinations. However, they can be a good assistant, as long as users are willing to verify generated texts with trustworthy resources.
What approaches are available for “accurate” generative AI applications?
For AIs to be able to offer more than just inspiration, it needs to provide reliable information.
Specifying domain for the generative AI
Clarifying the intended purpose of the LLM-derived product will enable users to clearly understand the limitations of the model. The LLM may contain some unassessed or unfiltered data, especially if it’s big. In this case, targeting a specific user segment makes it possible for users to have a realistic grasp on its accuracy.
For instance, it’s clear for users when to use a generative AI tool fine-tuned with more data on geographic knowledge. The risk of hallucination caused by the lack of or inappropriate information can be mitigated by making sure that the dataset contains comprehensive factual information on a particular subject.
Rigorous fine-tuning
Another option would be to fine-tune the model to a point where it can refuse to answer prompts to which it cannot provide accurate answers.
However, it’s important to note that generative AIs are not aware if its answers are factual or not. Hallucination and factual errors are based on multiple factors, including noisy data points and even forced training.
Using or building language models trained exclusively on factual information
Some models take a different approach when it comes to training language models. Some companies that aim to develop accurate generative AIs rely on carefully curated datasets from trusted sources, such as academic journals or verified databases. They may also use natural language processing techniques to help filter out inaccurate information from their training data.
For instance, generative AI startup Writer develops their own large language model with an encoder-decoder architecture designed to value accuracy over creativity. Beyond the architectural level, the startup mentions the importance of data. It ensures users that they only use accurate, real-life data to train its LLM. Depending on the purpose of using the generative AI, one can actively opt for such model design that focuses on accuracy rather than creativity.
Moving toward a data-centric approach
The usage cases for these text-based generative AIs are nearly limitless. They can promote workplace efficiency in various domains like marketing, law, computer science, and even education. Some of them show exceptional abilities to offer creative outputs, and the factor of entertainment has definitely been integral to their wide success in the general public.
The continued research on model-centric approach has been integral to realizing the impressive potential of generative AI technology. It’s widely considered that LLMs have almost reached its full bloom when it comes to model architectures, particularly after transformers.
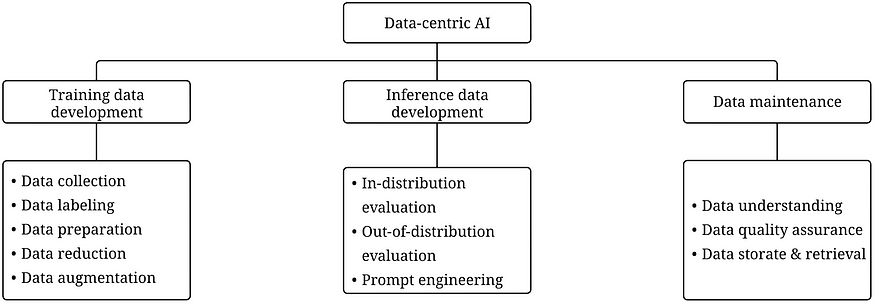
Meanwhile, there is a discrepancy in the level of accomplishment that can only be solved on a data level. Many of the problems that inhibit generative AIs from being reliable, including hallucination and problematic tone-and-manner, can be addressed by feeding the right data and continuing good maintenance of the model so as to avoid being outdated.
Beyond providing entertainment, usage safety must also be carefully considered when deploying or adapting artificial intelligences. For this, it is about time to more actively discuss the promotion of a data-centric approach for artificial intelligence development.