Language barriers have been a long-time concern for mankind and various efforts were made to overcome them.
And we are witnessing the way how technology makes it possible to overcome them: Machine translation has evolved along with advanced technology.
If you are in your 40s or over, you probably understand how the quality of automatic translation has greatly improved.
Brief History of Machine Translation (MT)
‘Machine translation’ may remind you of a few well-known online automatic translators.
And you might be quite surprised to know that it is in 1949 when the term ‘machine translation’ was first mentioned in Warren Weaver’s paper.
In the 1950s, Weaver implemented machine translation research in major universities in the U.S. such as MIT, the University of Washington, the University of Michigan, and in many countries such as Russia and France.
What we have now is the result of several steps of evolution.
Rule-Based Machine Translation (RBMT)
From the 1950s to the 1980s, the ‘Rule-Based Machine Translation(RBMT)’ has been at the center of research.
In this method, the translation is done according to the rules pre-entered by the person. This method generated a huge inconvenience that you had to input the rules of different languages into the computer every time you tried to translate new languages.
Furthermore, since this method required the professional linguists in the process of development, it took a lot of time to develop multilingual translation system and a lot of money to hire the linguists.
Corpus-based Machine Translation (CBMT)
Machine translation has experienced a big leap thanks to the corpus-based machine translation method that appeared around 1990.
Corpus-based machine translation is largely divided into Example-based Machine Translation and Statistical Machine Translation.
Example-based Machine Translation (EBMT) stores information of the source text and the target text, and utilizes the stored information in the event of a translation request of the same sentences.
But this method had some problems: it always requires the input of each corpus and at the same time synonym and antonym relations.
Statistical Machine Translation (SMT) leads to selecting a sentence with a high probability to respond to the original text in the translation.
This method consists of three stages: (a) dividing the original text into each word or phrase, (b) translating each unit, and (c) recombining the units into one sentense.
Then the option of greater probability is to be selected at step (b) and (c), by assessing which words are more used in the actual sentences, and which sentences have higher similarity among possible combinations.
That is why sufficient data accumulation is crucial with SMT. A typical example of this is Google Translate, which first launched in 2006.
SMT actually had some limitations: When the order of the two languages is different, the order of sentences comes out awkwardly, or the same word is translated differently according to the context.
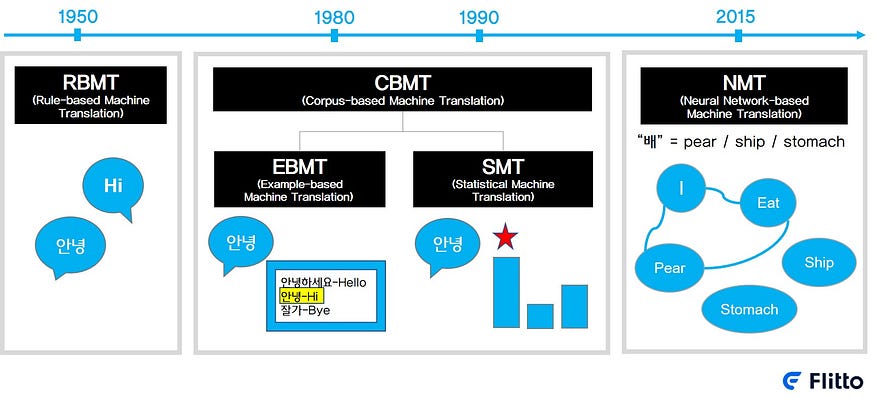
Neural Network-based Machine Translation (Neural Machine Translation, NMT)
The limitations of SMT have been largely addressed since the 2000s, with the introduction of Deep Learning (DL) technology.
Deep Learning is the most advanced artificial intelligence (AI) technology that is used to cluster or classify objects or data.
Neural Network Machine Translation (NMT) method using Deep Learning does not translate each word but learns and translates by reconstructing words, word order, and grammar from the original text.
With SMT, it is impossible to distinguish whether the word ‘right’ is ‘correct’, ‘just’, or ‘opposite to left’. However, NMT allows more accurate translation since it uses context to choose the right word.
Since 2016, Google Translation has seen a significant improvement of translation quality by introducing neural network machine translation technology for eight languages such as Korean, English, Chinese, French, Spanish, Japanese and Turkish.
The problems with SMT method such as wrong word orders or inappropriate words for the context have been solved with NMT.
However, artificial neural network-based method is not perfect either: it takes a lot of training time and resources, and it is difficult to translate for the languages that are not frequently used.
Trend Forecast for Corpus Data
With the ‘Metaverse’ gradually risen in popularity, the method and requirements for collecting a corpus have been changed.
Metaverse is a digital world where people can actively show themselves — with or without their own avatars — share their feelings and thoughts, and do all communication activities with anyone from any country. This means that we need not only functional translation but also non-verbal elements translation such as voice, tone, and situational context.
In this trend, the demand for specialized translation and hyper-personalized translation is rising. Accordingly, the direction of corpus construction is also gradually changing towards specialization and hyper-personalization.
If you look into Flitto’s language data, you can clearly see the difference the data sold before and after the year 2020: Our sales volume of the corpus itself has increased by seven times, and more importantly, the types and requirements of corpus have become more subdivided and diversified with multilingual corpus, specialized corpus by field, domain-specific corpus by field, etc.
Flitto forecasts that the constuction of corpus will go in a quite different direction than before:
- In order to build and collect corpus composed of more natural expressions of our daily life, the collaborative works with various social media platforms and websites will be more activated.
- Artificial Intelligence(AI) translators organically linked to the corpus collection enables immediate data refining and training.
- We will see more and more companies specializing in corpus data collection.

Flitto, with its in language big data and AI technology, is taking lead in efforts to collect and build multilingual corpus.
Flitto is operating the platforms called Flitto Lite and Flitto Arcade, where people can request translation anytime and language fluent users can instantly respond to them and get some rewards. All the data is collected on the mobile app and on the web with the consent of users, and Flitto’s own AI engine learns this data collected and refined in real time.
If companies and organizations want to collect the corpus data designed for their own business and projects, they can introduce Flitto’s platform by cloud or on-premises API. Once a corpus is built with their collected data, more data can be produced based on that corpus, which will eventually bring enormous quality data to the company.
Language is alive and tends to change. More diversified, more refined up-to-date corpus data is what you would need in order to make success in any related businesses. It is time to choose the right partner for the right data.