
In more ways than one, artificial intelligence (AI) image generation technology continues to amuse and terrify people in and out of the industry.

The winning of an AI-generated art at a fine arts competition has brought forth fierce conversation around the genre of digital art.
The artist stood by the legitimacy of his win. He explained that the quality of the final work had a lot to do with vigorous fine-tuning and prompt engineering as an artist; AI was just his choice of medium.
This event highlights the astonishing advancements of AI art. All it takes is some detailed prompts from skilled experts like the emerging prompt engineers and a bit of touch-up if necessary.
In generating these works of robotic art, good prompts are crucial.
It’s rarely effective to use simple keywords as prompts. Long strings of keywords and specs, and highly specific phrases greatly assist the robot artist in generating the work accurately.
The effect and limitation of good prompts
Many advanced AI image generation models are publicly available.
Midjourney is one such model; it has had 2.7 million members using its Discord server as of 2022.
To visualize the effects and limitations of prompt refining in AI artworks, we will be using Midjourney as our main robot designer for today (unless explicitly credited otherwise).
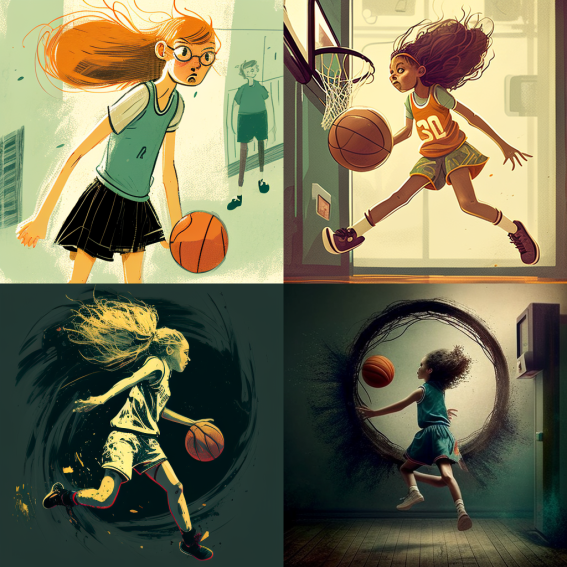
The four images above have been generated based on a simple one-liner prompt: “girl playing basketball.”
They are not terrible, but there is a lot going on.
The styles of the four images are inconsistent and broad. This makes them likely to miss the creative intentions of the user.
This is where the necessity of detailed prompts enters the conversation.
Next, we will try to apply some techniques used by prompt engineers to produce high-quality artworks. This technique involves writing prompts that can be better understood by machines.
Usually, machine-friendly prompts involve multiple phrases clearly specifying numbers and specs required. This enables the AI engine to have a better chance of recalling the right set of images.
To the prompt above, we added more details so that the bot could better understand what we expect it to create.
The revised prompt is: “a smiling girl shooting a basketball at an outdoor basketball court. upper body shot with full arms. photorealistic. 8k high resolution. extremely detailed, no filter — ar 16:9.”

We can see that the results have visibly become more specific. They are almost life-like like what we have asked (although imperfect. Note the complete absence of a basketball in the second image and the absence of a hand in the last image).
However, it’s important to note that detailed prompts in themselves do not guarantee foolproof results.
Below, we have input a specific prompt: “renaissance-style art of a 17th century lady in a victorian dress elegantly holding a smartphone. ornate golden circular frame in the background. detailed, bright cinematic lighting, high resolution 8k — ar 3:2.”

At a single glance, the images generated seem to correctly depict what the engine’s been told to depict.


Except for the hands.
Even when producing results that generally adhere to the descriptions provided, AI engines still seem to have a hard time figuring out how human hands are supposed to look like.
So what causes AI hands to look so bad?
The “horrifying AI hands” issue has been raised in multiple articles and communities. It is an ongoing struggle for many of the available models.

Some even suggest that it would be the current best practice to avoid requiring visible hands in prompts for optimized AI art results (e.g., by using gloves).
But what could be causing these anomalies in the first place? Flitto DataLab has sorted three possible reasons for it.
One: The inherently challenging features of human hands
Hands and feet are some of the most complex human body parts. A hand has 27 bones; a foot has 26.
Moreover, their unique structure lets the body part branch out and fold into several complex directions. It requires the artist to consider the unique perspective per each finger.
In fact, the intricacies of the hands as a subject of art challenge many human artists in drawing them accurately, not only AI artists.

However, AI models are able to emulate other intricate human features. So the “inherent” complexity of a certain body part can’t be a sufficient excuse these impossible finger positions.
Two: The limitations in AI image generation mechanism
Many of the AI image generation models utilize a “diffusion model” to create images.
In the diffusion model, the AI model is trained with a dataset of images labeled with texts.
As the training process begins, the images are gradually cluttered with random pixels. Through this process, the AI model learns to recognize what the underlying image contains in spite of the layer of pixels that obscures the image.
Next, the model is trained to “subtract” the added noises so that it can return clear images on its own.
Once sufficient training is done, the AI model will have become capable of generating its own images out of pure noise that contains no information.
In other words, AI models are only able to produce predictive results based solely on the 2D images with which it has been trained.
This boils down to the model using probabilities to guess where the fingers could be located on a flat image, without actually understanding the whole structure of a three-dimensional “hand.”
For the same reason, many AI models also have a difficult time producing the right amount of teeth or formulating letters and words into images.
Many publicly available AI image models are also character-blind. They merely attempt to combine lines and curves into something that look like letters, not understanding what they are supposed to mean when put together.
For instance, below is the image to the prompt: “magazine cover that says ‘BEWARE: DOG’ with a photograph of a cool golden retriever with sunglasses at a pool party.”

Three: Insufficient data on hand images
The above examples contain results commonly expected in the more publicly released AI image generation models.
However, as Google researchers and other experts see it, there exists a more concrete resolution to this phenomenon.
Google’s Parti was able to partially address a similar issue by simply incorporating a larger number of parameters — up to a whopping 20 billion.
Parti, one of the current state-of-the-art image generation engines, demonstrates an advanced capability to render symbols and texts.

It can be observed that the number of parameters greatly affects the overall quality of the results, including the text.
Under a similar mechanism, incorporating a more comprehensive dataset containing high-quality hand images could improve engine performance.
A Stability AI spokesperson pointed out that human hands tend to be less represented in images compared to human faces, wherein the former is often unclear or shown in smaller sizes.
Associate professor of AI at the University of Florida, Amelia Winger-Bearskin, also says that if every single image of human hands contained a full, perfect shot of hands, then the AI-reproduced versions of hands would also look perfect.
Conclusion
We have looked into the three reasons that contribute to the inability of AI models to emulate convincing human hands.
Each reason is attributed to the challenge presented by 1) the subject, 2) the machine, and 3) the data. There are still active research going on to address the latter two challenges.
Some may argue that because generative AIs are largely based on an algorithm that is still seemingly random to us, luck is an important factor. True enough, the currently available SOTA models can render decent-looking hands when accompanied with multiple attempts of fine-tuning the prompts.
However, being able to generate a typical hand would just be the beginning among many necessary milestones underway in order for a text-to-image model to live up to its name.
Ideally, image-generating models should be able to return results that users intended to bring — from commands like “slender, delicate hands” to “hand with six fingers including an additional thumb.” This milestone presupposes a model trained to have a decent “understanding” on hands, which in turn presupposes a strong foundation backed by an aptly sized initial dataset.
The generative AI in the field of images is expected to be a powerful tool as soon as these points are better addressed.
As a part of this ongoing narrative, Flitto DataLab will continue to keep the conversation going.