
Part 1 of the ACL 2023 Review Series
Cover image courtesy of ACL 2023 website
Some of the best NLP papers and researches of 2023 are here!
The year 2023 marked revolutionary progress in the natural language processing and machine learning field. Large language models like GPT, Bard, and LLama had made their presence felt. At Flitto DataLab, we continue to be at the forefront of computational linguistic technologies, particularly multilingual translation.
As such, we couldn’t miss out on the 61st Annual Meeting of the Computational Linguistics (ACL 2023). These are some presentations on the best NLP papers we thought might interest you.
Do Androids Laugh at Electric Sheep?—Best Paper Award
Jack Hessel, Ana Marasovic, Jena D. Hwang, Lillian Lee, Jeff Da, Rowan Zellers, Robert Mankoff and Yejin Choi.
Jack Hessel, a researcher at AI2, collaborated with fellow data scientists to investigate large language models’ capability to understand jokes like humans do. It’s commonly known that ChatGPT can generate jokes when prompted to. Some LLMs, such s PaLM, can also explain jokes quite successfully. And this begs the question:
Question: Can a deep learning model truly understand humor?

The author suggested that AI models have yet to develop a sense of humor as humans do. He provided an example where ChatGPT failed to successfully deliver a joke involving plays on words. This prompted his team to conduct a series of experiments to evaluate if LLMs are, indeed, capable of genuinely interpreting humor.
Methodology: Ask LLMs to choose captions; Humans score them
To conduct a structured experiment, Jack’s team turned to The New Yorker, a cartoon publication that has been circulating for almost 100 years. These days, the publication runs a weekly Caption Contest, where readers are invited to submit their cartoon captions. Then, panelists will vote on the best caption.
Jack devised a test where selected LLMs must perform a series of tasks based on The New Yorker Caption Contest:

- Matching an appropriate caption to a cartoon.
- Choosing the best amongst two captions and comparing it against the one voted by top editors.
- Explain why a joke is funny in 2-4 sentences.
To prepare the language models for the experiment, the researchers curated an annotated corpus consisting of hundreds of cartoons with locations, descriptions, uncanny highlights, and entity links. They also collected a corpus of joke explanations.
Findings: Fine-tuned LLMs can do well, but not quite well yet

In their experiments, Jack found that Clip ViT-L, fine-tuned on the annotated corpus, achieved 62.3% accuracy in the matching task. They also tested a 5-shot GPT-4 model with human-authored descriptions of the image, which produced an 84.5% accuracy. All the tested models failed to better the 94% matching accuracy charted by humans.
Likewise, humans perform comparatively better than GPT-4 in explaining a joke. Jack cited how GPT-4 committed several errors compared to a human’s explanation in his presentation. Nevertheless, this presentation allows us to understand the limitations and possibilities of using LLMs in interpreting jokes.
From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models—Best Paper Award
By Shangbin Feng, Chan Young Park, Yuhan Liu and Yulia Tsvetkov
NLP models are prone to bias, as they are trained from web-crawled data leaning towards different political beliefs. Most LLMs are trained on data from the likes of the New York Times, The Guardian, Hubpost, Washington Post, and major publications, which carry their own political leaning.
Question: What are the causes and implications of political biases in language models?

In this presentation, Shangbin Feng and his fellow researchers attempt to uncover the impact of political biases in pretraining data. Specifically, he explored how political biases propagate from training datasets into language models and subsequently to the respective downstream tasks. To do that, Feng designed a study to:
- Evaluate the political leaning of language models.
- Identify the role of pretraining data in political biases.
- Compare the performance of language models with different political leanings.
- Ascertain if a language’s political leaning lead to unfair NLP applications.
Methodology: Train language models with pretraining data from different sources, and prompt them
They prompted the language model with prompts designed to carry specific political insinuations, such as the political compass test. In their initial findings, multiple language models are either authoritarian, libertarian, and left or right-leaning. For example, they discovered that GPT-4 is the most liberal model.

Next, they investigated if such political leaning was inherited from the data bias of pretraining data. So, they further pre-train RoBERTa and GPT-2 on news media and social media datasets with different political leanings and data bias.
Result: Data bias manifests accordingly in downstream tasks
The result showed an apparent political shift in both models when trained with the biased data from respective media. For example, RoBERTa shifted substantially left when trained with data from Reddit.
Another interesting observation from the study was a noticeable political shift in the model when trained with data before and after the 45th US presidential election. This indicates the model’s capability to pick up societal polarization, which hints at how they would fare in fake news and hate speech detection.
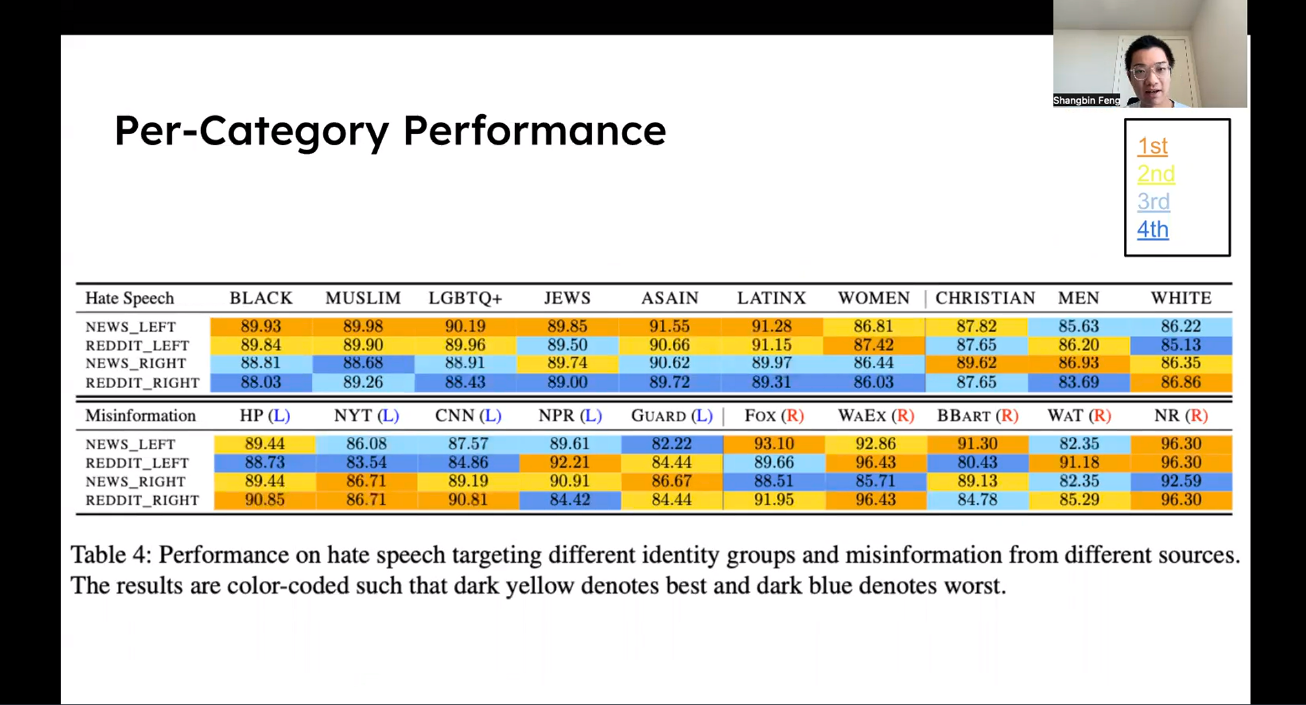
Feng concluded that models trained with left-leaning data work better in detecting hate speech targeting socially-minority groups. Meanwhile, white-leaning models are more accurate in detecting hate speech targeting white men. The researchers observed similar patterns in models pre-trained for detecting misinformation. Therefore, creating a ‘fair’ model lies in striking the delicate balance of how much one should sanitize training data from their political bias.
Weaker Than You Think: A Critical Look at Weakly Supervised Learning—Special Theme Paper Award
By Dawei Zhu, Xiaoyu Shen, Marius Mosbach, Andreas Stephan and Dietrich Klakow
First, what is “Weakly Supervised Learning (WSL)”?
Weakly supervised learning (WSL) is an approach to train machine learning models using weak labeling sources. These sources are not manually labeled but derived through labeling via knowledge bases or simple heuristic rules. The approach is attractive to organizations because it is scalable and less dependent on human labelers. Moreover, some studies suggest that WSL performs optimally when applied to models that generalize well.
Question: Is WSL really enough?
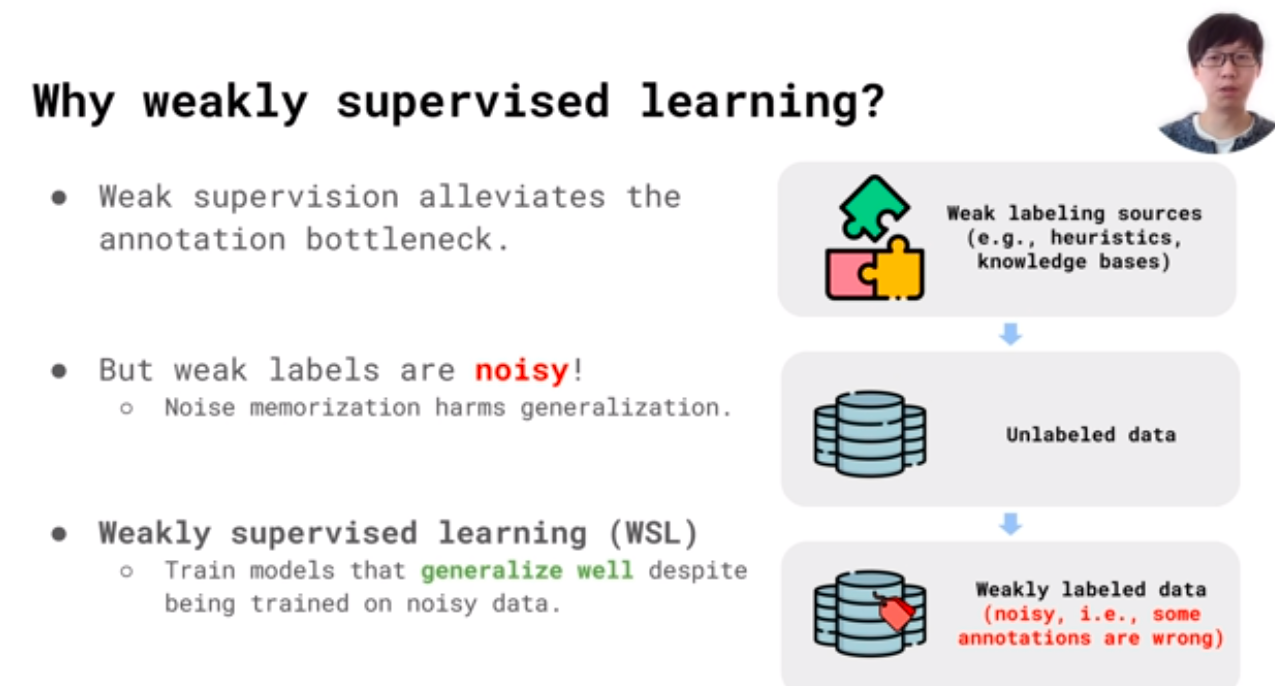
In this session, presenter Dawei Zhu from Saarland University and fellow researchers seek to debunk such claims. In his opening argument, he pointed out that WSL only performs well when cleanly labeled validation data are added to the equation. Unfortunately, the fact was often overlooked when claims were made about a WSL model’s superior performance.
So, they created a series of experiments to answer the following critical questions.
- Is clean validation data necessary?
- How many clean samples does WSL need?
- How to use the available clean samples more efficiently?
Let’s look at the results.
Findings: Relying on WSL isn’t the best choice

Their findings validated the assumption that clean, validated data is essential to ensure the model performs reasonably well. Otherwise, the models fail to generalize beyond the specificity of the weak labels, rendering the entire training meaningless. On the same note, increasing the number of cleanly validated samples will improve the model’s performance. Dawei suggested that using 20 samples per class is usually enough for the model to perform adequately.
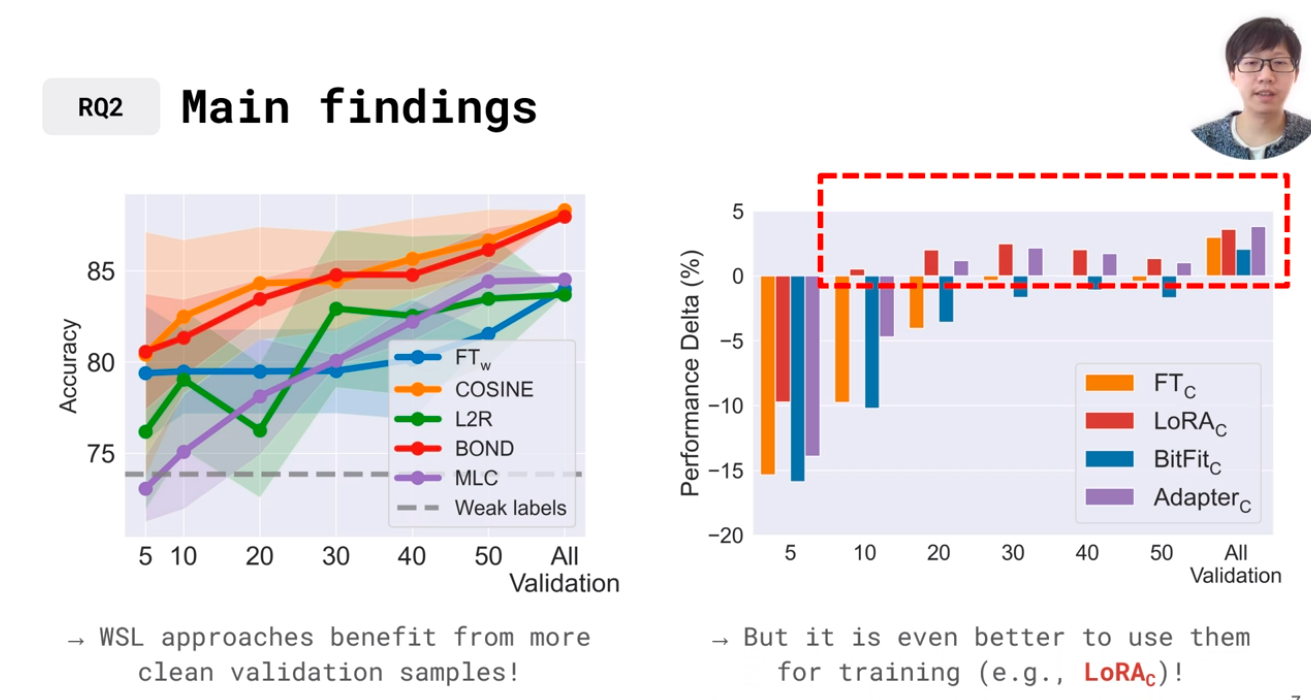
The experiment then turned interesting when Dawei’s team finetuned the model on the clean sample. They achieved better results than training the model with weakly supervised data. Further experiments reveal that a simpler WSL model can match or outperform more complex models when it continuously trains with clean samples.
This session reveals the recent popularity of the WSL approach needs a reality check. Rather than using weakly supervised learning unsparingly, it’s better to apply continuous fine-tuning with clean samples to train an accurate model.
Wrapping up…
ACL 2023 covered some of the most recent and significant researches on natural language processing and artificial intelligence.
In this first session on the event’s recap, we’ve covered some of the best NLP papers to read in 2023. They’ve covered the importance of the right supervision and training when it comes to well-functioning AIs.
Flitto DataLab clearly recognizes such importance, and that’s why we help researchers and companies work with massive amounts of clean datasets and properly processed data.
Lastly, we’d like to send warm congratulations to all presenters at ACL 2023. Your work paves the way for advancements in the field of NLP.
————–
If you love catching up on the latest AI events, we also have a series covering The European Chatbot and Conversational AI Summit 2023. You might want to give it a read!