
Data-as-a-service (DaaS) refers to the range of solutions that provides organizations with on-demand access to data. It is important for many business applications, including artificial intelligence (AI) systems.
In the age of artificial intelligence, data is the lifeblood of innovation. For AI systems to continue being useful, the importance of data for the AI model cannot be stressed enough.
In this article, we’ll look at the comprehensive data-as-a-service lifecycle, covering the particular sets of solutions your AI product may need during each stage in the AI application development.
What constitutes as high-quality data in machine learning?
Working with the right Data-as-a-Service solutions should leave you with high-quality data to effectively enhance your model. Eventually, this high-quality data will help your model produce safer and more accurate outputs for end-users.
The following are some criteria for high-quality data when it comes to training AI systems:
- Accuracy – The data should have been fact-checked and be free of any serious errors. Ideally, the accuracy rate should be no lesser than 95 percent per dataset.
- Balance – The distribution of classes should be balanced in order to avoid biased models.
- Timeliness – The data must contain updated and timely information, especially if the purpose of the model is to provide information.
- Diversity – The data should be representative of the real world.
- Safety – The data must be copyright-safe and non-invasive, so as not to infringe anyone’s rights. Any sensitive data information must be anonymized and protected.
High-quality language data, for instance, is an indispensable component in building and enhancing natural language processing (NLP) systems that make many exciting technologies come to life.
But the amount of existing language data is more limited than one might think, and even more so for high-quality ones. In fact, a research estimates that we will be running out of new high-quality data for AI models by the year 2026.
This imminent deficiency can be mitigated with the generation of new high-quality data that suits each need.
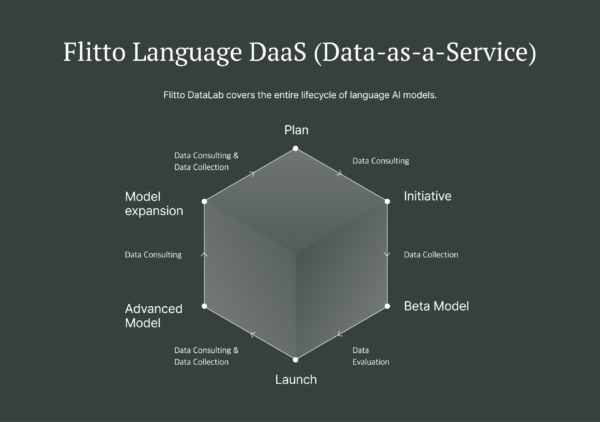
Data-as-a-Service pipeline for each AI product stage
There is no “one-size-fits-all” approach here; Each stage of the product cycle must be met with special attention. If your product or model is in its early development stage, you will need a different strategy from those with advanced AI products. The same goes for the other way around.
Let’s break down the data-as-a-service solutions into three broad processes in line with the different stages of AI product development, so that you can start mapping out which steps to take next.
Data Consultation
The data consultation process is the starting point of every data project we handle. This is where we can establish a clear understanding on the goals of your AI product, so that we can devise the roadmaps we can take in order to achieve them.
By understanding your objectives, we can also work out on the scope of the project. This helps us define the requirements for the new datasets or solutions.
Afterward, Flitto DataLab’s experts can provide various possible solutions to execute the plan. There are multiple fields of expertise to consider; not only in terms of technicalities like model compatibility and dataset build, but also in terms of privacy regulations and principles of non-disclosure.
Data Services
The data collection or processing stage is the highlight in the data-as-a-service cycle. This is where we take the definite scope of the project defined during the consultation process and begin working with the data.
We can classify these data services into three big branches.
Data Collection
A new data collection project can fill up the space that cannot be filled with off-the-shelf datasets. For instance, if you are developing a model that strives to be state-of-the-art, you will need to scale beyond the currently available datasets, especially for lower resource languages.
Otherwise, if your AI product has been released as a beta service or is going through an advancement phase, you might be aware of the specific weaknesses of your current model. If these weaknesses are specifically caused by a lack of relevant data (e.g. Model has difficulty understanding English spoken by speakers from non-English-speaking regions), counterpoising the deficient data will help bolster the model. Make sure that it comes with the right demographic metadata for the best results.
Data Processing
Data processing usually follows data collection. This solution makes the data trainable through due processing, such as transcribing and labeling.
For instance, you might already have a platform that gives you access to raw data that is non-invasive to users’ privacy (e.g. comments), and want to utilize that data to train existing or launch a new AI product. In this case, you have a gold mine in your hand! You just need to find data processing solutions like labeling entities, classes, sentiments, or topics that can help you move toward your product goals.
Data Evaluation
Data or model evaluation is a crucial stage if you want to take your existing model to the next level.
It serves two general purposes:
- To objectively measure the current capacity of the model through targeted user feedback
- To utilize the feedback itself as the model’s training data (e.g. Reinforced learning from human feedback (RLHF))
Because this process is closer to perfecting the models, it’s important to make sure that only qualified participants join this type of project.
Find the right Data-as-a-Service for each stage of AI product development
We’ve looked at the data-as-a-service pipelines for building the right AI data for each product development stage.
AI is a field just starting to bloom, and it’s truly an exciting era for innovators.
At Flitto DataLab, we also envision a world where AI systems are safe and effective, and that is why we work together with 13 million users on our global platform to help realize it by scaling the right language data.
For any unanswered questions in this article, please feel free to reach out to us. Meanwhile, we’ll be back with more useful information to take your AI product further.